– കുതിരവട്ടം പപ്പു, “ചന്ദ്രലേഖ”യില്.
ആണവ (അറ്റോമിക്) ചില്ലുകള്, ജോയിനറുകള്, ZWJ, ZWNJ തുടങ്ങിയ വാക്കുകള് ഉപയോഗിച്ചു കുറേക്കാലമായി സിബു, റാല്മിനോവ്, അനിവര്, പ്രവീണ്, സുറുമ, സന്തോഷ് തോട്ടിങ്ങല് തുടങ്ങിയവര് തിരിച്ചും മറിച്ചും സാങ്കേതികവും സര്ക്കാസ്റ്റിക്കും ആയി പോസ്റ്റുകള് ഇറക്കുന്നുണ്ടു്. ഇതൊക്കെ വായിച്ചു് ചന്ദ്രലേഖയിലെ പപ്പുവിനെപ്പോലെ “എന്താ ഈ ആണവചില്ല്?” എന്നു ചോദിച്ചു് അന്തം വിട്ടു കുന്തം വിഴുങ്ങി ഇരിക്കുന്ന ബ്ലോഗുവായനക്കാര്ക്കു വേണ്ടിയുള്ളതാണു് ഈ പോസ്റ്റ്.
എന്തുകൊണ്ടു ഞാന് ഇതെഴുതുന്നു എന്നു ചോദിച്ചാല്,
- മലയാളഭാഷയെപ്പറ്റി കുറെയൊക്കെ അറിഞ്ഞിരുന്നെങ്കിലും യൂണിക്കോഡിനെപ്പറ്റിയുള്ള അജ്ഞത മൂലം ഞാനും കുറേക്കാലം ഇങ്ങനെ കുന്തം വിഴുങ്ങി ഇരുന്നിട്ടുണ്ടു്. പിന്നെ കാര്യങ്ങള് കുറേശ്ശെ വ്യക്തമായി. വ്യക്തമായതെങ്ങനെ എന്നു വിശദീകരിച്ചാല് ഇപ്പോള് കുന്തം വിഴുങ്ങിയിരിക്കുന്നവര്ക്കു് സഹായകമാകും എന്നൊരു ചിന്ത.
- അറ്റോമിക് ചില്ലുകളെപ്പറ്റിയുള്ള ചര്ച്ചകളിലെ ഭാഷാപരമായ കാര്യങ്ങളില് അഭിപ്രായം പറഞ്ഞിട്ടുണ്ടെങ്കിലും, ഞാന് ഇതു വരെ അവയെ അനുകൂലിച്ചോ എതിര്ത്തോ പറഞ്ഞിട്ടില്ല. ഈ വിഷയത്തെപ്പറ്റി എനിക്കുള്ള അഭിപ്രായം വ്യക്തമാക്കാന് കൂടിയാണു് ഈ ലേഖനം.
യൂണിക്കോഡിനെപ്പറ്റിയും അതില് മലയാളം ഉപയോഗിക്കുന്നതിനെപ്പറ്റിയും നല്ല പല ലേഖനങ്ങളും ഇതിനകം ഉണ്ടായിട്ടുണ്ടു്. ഈ കാര്യങ്ങള് ക്രോഡീകരിച്ചു് സിബു വരമൊഴി വിക്കിയില് ഇട്ടിട്ടുള്ള ഈ ലേഖനം ആണു് അവയില് ഒന്നു്. ഇതു വായിക്കുന്നതിനു മുമ്പു് അതു വായിക്കുന്നതു നന്നായിരിക്കും.
ആദ്യമേ ഒരു അറിയിപ്പു്: മൈക്ക് ടെസ്റ്റിംഗ്, വണ്, ടൂ, ത്രീ,…
ദയവായി ഈ പോസ്റ്റ് ഈ ബ്ലോഗില്ത്തന്നെ വായിക്കുക. ഫീഡ് റീഡര്, ഈ-മെയില് തുടങ്ങിയവയിലൂടെ കടന്നു പോയാല് പല ജോയിനറുകളും നഷ്ടപ്പെട്ടു് ഉദ്ദേശിച്ചതു തെറ്റും എന്നതുകൊണ്ടാണു് ഇതു്. മറ്റു രീതിയില് വായിക്കുന്നവര്ക്കായി ഈ പോസ്റ്റിന്റെ ലിങ്ക്: http://malayalam.usvishakh.net/blog/archives/288.
അതുപോലെ ന് (ന + വിരാമം + ZWJ) എന്നതിനെ ന് എന്ന ചില്ലക്ഷരമായി കാണിക്കുന്ന (ന് എന്നു നയുടെ കൂടെ ചന്ദ്രക്കല ഇട്ടതല്ല) ഏതെങ്കിലും ഓപ്പറേറ്റിംഗ് സിസ്റ്റം/ബ്രൌസര് ഉപയോഗിക്കുക.
എന്റെ അറിവില് താഴെപ്പറയുന്ന കോംബിനേഷനുകള് ശരിയായി ചില്ലുകള് കാണിക്കുന്നു:
- Windows + IE
- Windows + Firefox 3.0
- Windows + Firefox 2.0 + IE tab
- Linux + Firefox 3.0 + Rachana/Meera font
- Linux + Firefox 2.0 + Rachana/Meera font + Suruma’s Pango patch
അല്ലെങ്കില് താഴെയുള്ളതു നല്ല തമാശയായിരിക്കും. ശയും ഷയും ഒരു പോലെ ഉച്ചരിക്കുന്ന ഒരുത്തന് ഒരിക്കല് എന്നോടു് “ഉമേഷേ, ഉമേഷിന്റെ പേരു ശരിക്കു് ഉമേശ് എന്നല്ലേ പറയേണ്ടതു്, അതെന്തിനാ ഉമേഷ് എന്നു പറയുന്നതു്?” എന്നു ചോദിച്ചതും ഞാന് അന്തം വിട്ടു നിന്നതും ഓര്മ്മ വരുന്നു 🙂
ഒരു ഉദാഹരണം:
ഒരു ഉദാഹരണത്തില് തുടങ്ങാം.
ആദ്യമായി ചില്ലക്ഷരങ്ങളെ കാണിക്കുന്ന ഏതെങ്കിലും ഓപ്പറേറ്റിംഗ് സിസ്റ്റം/ബ്രൌസര്/ഫോണ്ട്/സേര്ച്ച് എഞ്ചിന് ഉപയോഗിച്ചു് അവന് എന്ന വാക്കൊന്നു സേര്ച്ചു ചെയ്തു നോക്കുക. വിന്ഡോസ് എക്സ് പി/ഇന്റര്നെറ്റ് എക്സ്പ്ലോറര് 7/കാര്ത്തിക/ഗൂഗിള് ഉപയോഗിച്ചു ഞാന് നടത്തിയ തിരയലിന്റെ ഫലം താഴെ.
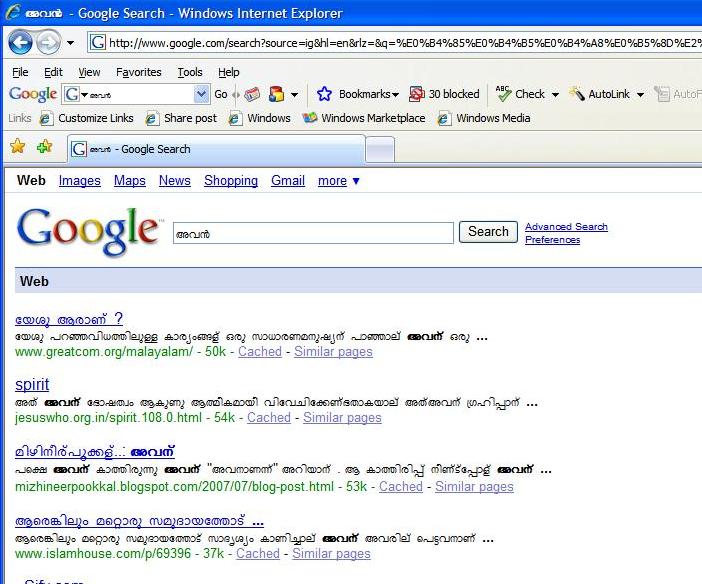
അവന് എന്നതു തിരഞ്ഞപ്പോള് കിട്ടിയതു് അവന് എന്നാണു് എന്നു തോന്നും. ഇവയില് ഏതെങ്കിലും ഒരു ഫലത്തില് ക്ലിക്കു ചെയ്തു നോക്കിയാല് അതു് അവന് എന്നു തന്നെയാണെന്നു കാണാം. അതായതു്, സേര്ച്ച് എഞ്ചിന് ശരിയായ വാക്കു തന്നെ കണ്ടുപിടിച്ചെങ്കിലും സേര്ച്ച് ലിസ്റ്റില് അതിനെ നാം കാണുമ്പോള് അതു് അവന് എന്നായി മാറി. (എല്ലാ ഓപ്പറേറ്റിംഗ് സിസ്റ്റം/ബ്രൌസര്/സേര്ച്ച് എഞ്ചിന് കോംബിനേഷനുകളിലും ഇതുണ്ടാവണമെന്നു നിര്ബന്ധമില്ല. ചിലതില് ഉണ്ടെന്നേ ഞാന് പറയുന്നുള്ളൂ.)
ഇതെങ്ങനെ സംഭവിച്ചു?
ചില്ലക്ഷരമായ ന് എന്നതിനെ ഇപ്പോള് സൂചിപ്പിക്കുന്നതു് (ഫോണ്ടുകള്, ഇന്പുട്ട് മെതേഡുകള് തുടങ്ങിയവ. യൂണിക്കോഡ് സ്റ്റാന്ഡേര്ഡ് ഇതിനെപ്പറ്റി ഒന്നും പറയുന്നില്ല) ന + വിരാമം + ZWJ എന്നാണു്. എവിടെയോ വെച്ചു് ആ ZWJ (സീറോ വിഡ്ത്ത് ജോയിനര്) നഷ്ടപ്പെട്ടു പോയിട്ടു നമുക്കു കിട്ടിയതു് ന + വിരാമം എന്നു മാത്രമാണു്. അതാണു് ന് എന്നു കാണുന്നതു്.
ദേ പിന്നെയും വന്നു കോണ്ടസാ. എന്താ ഈ ജോയിനര്, വിരാമം എന്നൊക്കെ പറയുന്നതു്?
ഓ, സോറി. അതു പറയാം.
ആസ്കി ഫോണ്ടുകളില് (ഉദാ: ദീപിക പത്രത്തിലെ ഫോണ്ടു്) ല എന്നതും ല്ല എന്നതും രണ്ടു കാര്യങ്ങളാണു്. തമ്മില് യാതൊരു ബന്ധവുമില്ലാത്ത രണ്ടു് അക്ഷരങ്ങള്. അവയെ സൂചിപ്പിക്കാന് രണ്ടു വ്യത്യസ്ത ആസ്കി കോഡുകള് ഉപയോഗിക്കുന്നു.
യൂണിക്കോഡില് സംഗതി വ്യത്യസ്തമാണു്. അവിടെ ല എന്നതും ല്ല എന്നതും ഒരു ബന്ധവുമില്ലാത്ത രണ്ടു കാര്യങ്ങളല്ല. അവിടെ ല്ല എന്നൊരു അക്ഷരമില്ല. അതു് ല + വിരാമം + ല എന്നു മൂന്നു സംഗതികള് ചേര്ന്നതാണു്. വിരാമം എന്നതു് അതിനു തൊട്ടു മുമ്പുള്ള അക്ഷരത്തെ ചില രീതിയില് വ്യത്യാസപ്പെടുത്തുന്ന ഒരു സ്പെഷ്യല് കാരക്ടര് ആണു്. ഇവിടെ അതു് ല എന്നതിലെ അകാരത്തെ കളഞ്ഞിട്ടു് ല് എന്ന ശുദ്ധവ്യഞ്ജനമാക്കുന്നു. സാധാരണയായി അതു ചെയ്യുന്നതു് ഒരു ചന്ദ്രക്കല ഇട്ടു് ആയതു കൊണ്ടു് ചിലര് അതിനെ “ചന്ദ്രക്കല” എന്നു പറയാറുണ്ടു്. പക്ഷേ വിരാമം ഉള്ളിടത്തൊക്കെ ചന്ദ്രക്കല ഉണ്ടാവണമെന്നില്ല. ഉദാഹരണം ല്ല എന്നതു തന്നെ.
അല്പം കൂടി വലിയ ഒരു കൂട്ടക്ഷരം നോക്കാം. ഗ്ദ്ധ എന്ന അക്ഷരം യൂണിക്കോഡില് എപ്പോഴും ഗ + വിരാമം + ദ + വിരാമം + ധ ആണു്. അതു കാണിക്കുന്ന ഫോണ്ടുകള് അതിനെ ഒറ്റ അക്ഷരമായോ ഗ + ചന്ദ്രക്കല + ദ്ധ എന്നോ ഗ്ദ + ചന്ദ്രക്കല + ധ എന്നോ ഗ + ചന്ദ്രക്കല + ദ + ചന്ദ്രക്കല + ധ എന്നോ കാണിച്ചെന്നിരിക്കും. (ഫോണ്ടിലോ ഓപ്പറേറ്റിംഗ് സിസ്റ്റത്തിലെ ലേ ഔട്ട് എഞ്ചിനോ ബഗ്ഗുണ്ടെങ്കില് വേറേ രീതിയിലും കണ്ടെന്നിരിക്കാം.) എങ്കിലും ആ യൂണിക്കോഡ് ടെക്സ്റ്റ് സൂക്ഷിച്ചിരിക്കുന്ന ഒരു ഫയലില് എപ്പോഴും 0D17(ഗ), 0D4D(വിരാമം), 0D26(ദ) 0D4D (വിരാമം), 0D27 (ധ) എന്നു് അഞ്ചു യൂണിക്കോഡ് കോഡുകളേ ഉണ്ടായിരിക്കുകയുള്ളൂ. യൂണിക്കോഡിലെ (പതിപ്പു് 5.0) മലയാളം കോഡുകള് ഏതൊക്കെയാണെന്നു് ഇവിടെ വായിക്കാം.
ഏതു തരം എന്കോഡിംഗ് ആണുപയോഗിക്കുന്നതു് എന്നതിനെ ആശ്രയിച്ചു് ഫയലിലുള്ള ബൈറ്റുകള്ക്കു് വ്യത്യാസമുണ്ടായിരിക്കും. ഉദാഹരണമായി മലയാളത്തിലെ ഓരോ കോഡിനും മൂന്നു ബൈറ്റു് ഉപയോഗിക്കുന്ന utf-8 എന്ന രീതിയില് (ഇതാണു് ഭൂരിഭാഗം വെബ്പേജുകളില് ഉപയോഗിക്കുന്നതു്) ഗ്ദ്ധ എന്നതിലെ അഞ്ചു യൂണിക്കോഡ് കോഡുകളെ E0 B4 97 E0 B5 8D E0 B4 A6 E0 B5 8D E0 B4 A7 എന്നു പതിനഞ്ചു ബൈറ്റുകള് കൊണ്ടു സൂചിപ്പിക്കുമ്പോള് മലയാളം കോഡുകള്ക്കു രണ്ടു ബൈറ്റു വീതം ഉപയോഗിക്കുന്ന utf-16 രീതിയില് അതിനെ 0D 17 0D 4D 0D 26 0D 4D 0D 27 എന്നു പത്തു ബൈറ്റുകളില് സൂചിപ്പിക്കുന്നു.
ഇനി വിദഗ്ദ്ധന് എന്നെഴുതുന്ന ഒരാള്ക്കു് അതു് ഗ + ചന്ദ്രക്കല + ദ്ധ എന്നു തന്നെ കാണണം എന്നു നിര്ബന്ധമുണ്ടെന്നിരിക്കട്ടേ. അതിനുള്ള വഴിയാണു് ZWNJ. Zero Width Non-Joiner എന്നതിന്റെ ചുരുക്കം. ഇവിടെ ഗ്ദ്ധ എന്നതിനെ ഗ, വിരാമം, ZWNJ, ദ, വിരാമം, ധ എന്നു സൂചിപ്പിക്കുന്നു-ഗ്ദ്ധ എന്നു കാണുവാന് വേണ്ടി.
മിക്കവാറും ടെക്സ്റ്റ് എഡിറ്ററുകളും ബ്രൌസറുകളും ഗയെയും ദ്ധയെയും വേര്തിരിച്ചു തന്നെ കാണിക്കും. പക്ഷേ, ഈ ടെക്സ്റ്റ് നെറ്റ്വര്ക്കിലൂടെ യാത്ര ചെയ്യുമ്പോഴോ ഡാറ്റാബേസുകളില് ശേഖരിച്ചിട്ടു തിരിച്ചെടുക്കുമ്പോഴോ ഈ-മെയില്, ഫീഡ് റീഡറുകള് തുടങ്ങിയ സ്ഥലങ്ങളില് പരിവര്ത്തനം ചെയ്യുമ്പോഴോ ഈ ZWNJ നഷ്ടപ്പെട്ടു പോയേക്കാം. കാരണം യൂണിക്കോഡ് സ്റ്റാന്ഡേര്ഡ് അനുസരിച്ചു് അതൊരു ഡീഫോള്ട്ട് ഇഗ്നോരബിള് കാരക്ടര് ആണു്. അങ്ങനെ സംഭവിച്ചാലും ഗ്ദ്ധ (ഗ + ചന്ദ്രക്കല + ദ്ധ) എന്നതു് ഗ്ദ്ധ (ഒറ്റ ഗ്ലിഫ്) ആയിപ്പോകുമെന്നേ ഉള്ളൂ. ഇതൊരു വലിയ പ്രശ്നമല്ല-കാണാന് അല്പം അലോസരം ഉണ്ടാക്കിയാലും.
ഇതു പോലെയുള്ള മറ്റൊരു ഡീഫോള്ട്ട് ഇഗ്നോറബിള് കാരക്ടര് ആണു് ZWJ (Zero Width Joiner). രണ്ടു കാരക്ടരുകളെ ഒന്നിച്ചേ കാണിക്കാവൂ എന്നാണു് ഇതിന്റെ അര്ത്ഥം. ഒരു ഉദാഹരണം ഇംഗ്ലീഷില് fi എന്നെഴുതുമ്പോള് അവ രണ്ടും ചേര്ത്തെഴുതി എന്നു കാണിക്കാന് f, ZWJ, i എന്നെഴുതുന്നതാണു്. ഇതു് fi എന്നു കാണിക്കും. ഇതിലെ ZWJ നഷ്ടപ്പെട്ടു fi എന്നായാലും വലിയ കുഴപ്പമൊന്നുമില്ലാത്തതിനാല് ഇവിടെ ZWJ ഉപയോഗിച്ചതില് തെറ്റില്ല. (ചേര്ന്നു നില്ക്കുന്ന fi-യ്ക്കും ഒരു പ്രത്യേക കോഡ് പോയിന്റുണ്ടെന്നതു മറ്റൊരു കാര്യം.)
മിക്കവാറും എല്ലാ സ്ക്രിപ്റ്റുകള്ക്കും ഈ ജോയിനറുകള് ഫോര്മാറ്റ് കാരക്ടറുകള് (അക്ഷരങ്ങള്ക്കു bold, italics തുടങ്ങിയ സ്വഭാവങ്ങള് കൊടുക്കുന്ന മാര്ക്കറുകള്) പോലെയാണു്. നഷ്ടപ്പെട്ടാലും അര്ത്ഥവ്യത്യാസമുണ്ടാവുന്നില്ല.
ചുരുക്കം ചില സ്ക്രിപ്റ്റുകളില് ജോയിനറുകള് ഫോര്മാറ്റ് വ്യത്യാസത്തില് അല്പം കൂടി കൂടിയ സെമാന്റിക് വ്യത്യാസമുണ്ടാക്കുന്നുണ്ടു്. കൂട്ടക്ഷരങ്ങള് (conjuncts) ഉള്ള ഇന്ത്യന് ഭാഷകളും അറബിയുമാണു് ഇവയില് പ്രധാനം. കൂട്ടക്ഷരങ്ങള് ഉണ്ടാക്കുമ്പോള് കര്ത്താവിന്റെ അഭിരുചിക്കനുസരിച്ചുള്ള രൂപം വരാന് ജോയിനറുകള് ഉപയോഗിക്കാതെ നിവൃത്തിയില്ല. പക്ഷേ ഇവിടെയും ജോയിനറുകള് അര്ത്ഥവ്യത്യാസമുണ്ടാക്കാതിരിക്കേണ്ടതു് ആവശ്യമാണു്.
അപ്പോള് സദ്വാരം, ഉമേശ്വരന്, വന്യവനിക, കണ്വലയം,…?
സദ്വാരം (സ + ദ്വാരം, സദ് + വാരം), ഉമേശ്വരന് (ഉമാ + ഈശ്വരന്, ഉമേശ് + വരന്) തുടങ്ങിയവയ്ക്കു രണ്ടര്ത്ഥം പറയാമെങ്കിലും അതു ഭാഷയുടെ പ്രത്യേകതയും പലപ്പോഴും സൌന്ദര്യവുമാണു്. (ഇതു സുറുമയും എവിടെയോ പറഞ്ഞിട്ടുണ്ടെന്നാണു് ഓര്മ്മ.) “പരമസുഖം ഗുരുനിന്ദ കൊണ്ടുമുണ്ടാം” എന്ന വരിയിലെ “പരമസുഖം” എന്ന വാക്കിനു ജോയിനറുകള് ഇല്ലാതെ തന്നെ രണ്ടു പിരിവുകള് (പരമ + സുഖം, പരം + അസുഖം) ഉണ്ടാകുന്നതു പോലെയാണിതു്. “സഭംഗശ്ലേഷം” എന്നാണു് ഇതിനെ കാവ്യശാസ്ത്രത്തില് പറയുന്നതു്. അര്ത്ഥശങ്ക ഉണ്ടാകരുതു് എന്നു നിര്ബന്ധമാണെങ്കില് പിരിച്ചു തന്നെ എഴുതുകയോ (സദ്-വാരം) ബ്രായ്ക്കറ്റിലോ ഫുട്ട്നോട്ടിലോ കൊടുക്കുകയോ ചെയ്യുക. വന്യവനിക (വന്യ-വനിക, വന്-യവനിക), കണ്വലയം (കണ്വ-ലയം, കണ്-വലയം) തുടങ്ങിയവയുടെയും സ്ഥിതി ഇതു തന്നെ. ഇതു ചില്ലുവാദത്തിനു് അനുകൂലമോ പ്രതികൂലമോ ആയ വസ്തുതയാണെന്നു് എനിക്കു തോന്നുന്നില്ല.
എന്തുട്ടാ ഈ ഐഡിയെന്നും സ്പൂഫിംഗും?
അറ്റോമിക് ചില്ലിനെ അനുകൂലിച്ചും എതിര്ത്തും ആളുകള് വാദിച്ചപ്പോള് IDN-നെപ്പറ്റിയും സ്പൂഫിങ്ങിനെപ്പറ്റിയും വളരെ പറഞ്ഞിരുന്നു. തികച്ചും ബാലിശമായ വാദങ്ങളാണു് അവ. ഒരു വെബ്പേജിന്റെ അഡ്രസ്സു പോലെ കാഴ്ചയ്ക്കു തോന്നുന്ന മറ്റൊരു അഡ്രസ് ഉപയോഗിച്ചു് ഉപഭോക്താക്കളെ വഴി തെറ്റിക്കുന്നതാണു് ഇവിടെ ഉദ്ദേശിക്കുന്നതു്. ഇതു് ഇന്റര്നെറ്റ് സെക്യൂരിറ്റി ഇഷ്യൂ ആണു്; യൂണിക്കോഡുമായി ബന്ധപ്പെട്ടതല്ല. ഉദാഹരണമായി, a എന്ന ആകൃതിയുള്ള അക്ഷരം പല ഭാഷകളിലുമുണ്ടു്. ഒന്നിനു പകരം മറ്റൊന്നുപയോഗിച്ചു് സ്പൂഫിംഗ് ചെയ്യാം. (“Paypal spoofing” എന്നൊന്നു സേര്ച്ചു ചെയ്തു നോക്കൂ. കൂടുതല് വിവരങ്ങള് കിട്ടും.)
മലയാളത്തിലും സ്പൂഫിംഗ് ഉണ്ടാക്കാന് ചില്ലുകള് എന്കോഡ് ചെയ്യുകയോ ചെയ്യാതിരിക്കുകയോ വേണ്ട. (രണ്ടു പക്ഷക്കാരുടെയും വാദങ്ങള് കേട്ടു മടുത്തു!) ഥ എന്ന മലയാള അക്ഷരത്തിനു പകരം മ (ம) എന്ന തമിഴ് അക്ഷരം ഉപയോഗിക്കാം. ട എന്ന മലയാള അക്ഷരത്തിനു പകരം എസ് (s) എന്ന ഇംഗ്ലീഷ് അക്ഷരം ഉപയോഗിക്കാം. മലയാളത്തില്ത്തന്നെ ന് എന്ന ചില്ലിനു പകരം 9 (൯) എന്ന അക്കവും ര് എന്ന ചില്ലിനു പകരം 4 (൪) എന്ന അക്കവും ഉപയോഗിക്കാം. അനുസ്വാരവും ഠ എന്ന അക്ഷരവും ഒ (o) എന്ന ഇംഗ്ലീഷ് അക്ഷരവും 0 എന്ന അക്കവും ൦ എന്ന മലയാള അക്കവും ഉപയോഗിച്ചും സ്പൂഫിംഗ് നടത്താം.
സ്പൂഫിംഗ് തടയുന്നതു് കൂടുതല് സങ്കീര്ണ്ണമായ വിഷയമാണു്. അറ്റോമിക് ചില്ലുകള് എന്കോഡ് ചെയ്യുന്നതും അതുമായി കൂട്ടിക്കുഴയ്ക്കുന്നതു് വിഷയത്തില് നിന്നു വ്യതിചലിക്കലാണു്.
അപ്പോള്പ്പിന്നെ എന്തിനാണു് അറ്റോമിക് ചില്ലുകള്? പാല് എന്നും പാല് എന്നും എഴുതിയാല് അര്ത്ഥം മാറുന്നില്ലല്ലോ?
മുകളില് പറഞ്ഞതു പോലെ, ജോയിനറുകള് നഷ്ടപ്പെടുന്നതു കൊണ്ടു വരുന്ന വിഷ്വല് ഡിസ്റ്റോര്ഷന് അറ്റോമിക് ചില്ലുകളെ അനുകൂലിക്കാനോ എതിര്ക്കാനോ ഉള്ള മതിയായ കാരണമല്ല. കാരണമാവണമെങ്കില് ജോയിനര് നഷ്ടപ്പെടുന്നതിനു മുമ്പും പിമ്പുമുള്ള രൂപങ്ങള് തികച്ചും വ്യത്യസ്തങ്ങളാവണം. അവയ്ക്കു് അങ്ങോട്ടുമിങ്ങോട്ടും മാറ്റാന് പറ്റാത്ത വിധം വ്യത്യസ്തങ്ങളായ അര്ത്ഥം ഉണ്ടാവണം.
ഇതു് ഒരു കാര്യത്തിലേ ഉണ്ടാകുന്നുള്ളൂ. അതാണു് അറ്റോമിക് ചില്ലു വാദികള് തങ്ങളുടെ തുറുപ്പുചീട്ടായി മുന്നില് വെയ്ക്കുന്നതു്. ആ കാരണമാകട്ടേ, മതിയായ കാരണമാണു താനും.
സംവൃതോകാരത്തെ ചില്ലില് നിന്നു വ്യവച്ഛേദിക്കുന്നതാണു് ആ കാരണം.
ദാ, അടുത്ത സാധനം. എന്താ ഈ സംവൃതോകാരം?
പണ്ടു് എന്നു പറയുമ്പോള് അവസാനം വരുന്ന ശബ്ദമാണു സംവൃതോകാരം. അതു് അ അല്ല, ഉ അല്ല, സംവൃതവുമല്ല. ഭാഷാശാസ്ത്രജ്ഞര് അതിനെ Schwa എന്നു വിളിക്കുന്നു. പല ഭാഷകളിലുമുള്ള ഒരു ശബ്ദമാണതു്. ഇതിനെ പ്രത്യേകമായി എഴുതിക്കാണിക്കാറുണ്ടു് എന്നതാണു് മലയാളത്തിന്റെ ഒരു പ്രത്യേകത.
പണ്ടു് എന്ന വാക്കിനെ പല തരത്തില് എഴുതിപ്പോന്നിരുന്നു. വളരെ പഴയ മലയാളത്തില് പണ്ട എന്നായിരുന്നു എഴുതിയിരുന്നതു്. ഗുണ്ടര്ട്ടു മുതലായ പാതിരിമാര് അതിനെ പണ്ടു എന്നെഴുതി. (“സ്ത്രീയേ, നിനക്കു എന്തു?” എന്നു പഴയ ബൈബിളില്.) അതേ സമയത്തു തന്നെ വളരെപ്പേര് (പ്രധാനമായും വടക്കന് കേരളത്തിലുള്ളവര്) അതിനെ പണ്ട് എന്നെഴുതി. (പണ്ടു എന്നതിനെ ‘പാതിരിമലയാളം’ എന്നു കളിയാക്കുകയും ചെയ്തു.) ഈ കാര്യങ്ങളൊക്കെ ഏ. ആര്. രാജരാജവര്മ്മ “കേരളപാണിനീയ”ത്തിന്റെ പീഠികയില് വിശദമായി പറഞ്ഞിട്ടുണ്ടു്. ഏ. ആറിന്റെ കാലത്താണു സംവൃതോകാരത്തിന്റെ പല രൂപങ്ങളെ ചേര്ത്തു പണ്ടു് എന്ന രൂപം സാര്വ്വത്രികമായതു്. ഇതു വളരെയധികം ആളുകള് ഉപയോഗിച്ചെങ്കിലും ഒരു നല്ല ശതമാനം ആളുകളും സംവൃതോകാരാത്തിനു ചന്ദ്രക്കല മാത്രം ഉപയോഗിക്കുന്ന രീതി തുടര്ന്നു വന്നു. 1970-കളില് പുതിയ ലിപി വ്യാപകമായപ്പോള് അതുപയോഗിക്കുന്ന എല്ലാവരും തന്നെ ഉകാരത്തിന്റെ ചിഹ്നമിടാതെ സംവൃതോകാരം എഴുതിത്തുടങ്ങി. ഇപ്പോള് അതാണു ബഹുഭൂരിപക്ഷം ആളുകളും ഉപയോഗിക്കുന്നതു് എന്നതാണു വാസ്തവം.
(ഇതിനെപ്പറ്റി ഉദാഹരണങ്ങളുള്ള പേജുകളുടെ പടങ്ങള് ചേര്ത്തു് സിബു പണ്ടു പ്രസിദ്ധീകരിച്ചതു് ഇവിടെ.)
എഴുത്തു തുടങ്ങിയപ്പോള് മുതല് ഉകാരത്തിന്റെ ചിഹ്നത്തോടു കൂടി മാത്രമേ ഞാന് സംവൃതോകാരം എഴുതിയിട്ടുള്ളൂ. ഇപ്പോഴും അതു തുടരുന്നു. ഒരു കാലത്തു് അതു മാത്രമാണു ശരി എന്നു ഞാന് ഘോരഘോരം വാദിച്ചിട്ടുണ്ടു്. (ഞാന് രണ്ടു കൊല്ലത്തിനു മുമ്പെഴുതിയ സംവൃതോകാരം, സംവൃതോകാരവും ലിപിപരിഷ്കരണങ്ങളും, സംവൃതോകാരത്തെപ്പറ്റി വീണ്ടും എന്നീ ലേഖനങ്ങള് കാണുക.) സംവൃതോകാരത്തെ ഉകാരത്തിന്റെ ചിഹ്നത്തോടൊപ്പം ചന്ദ്രക്കലയിട്ടെഴുതുന്നതു തെറ്റല്ല എന്നാണു് ഇപ്പോഴും എന്റെ വിശ്വാസം. എങ്കിലും അതു മാത്രമാണു ശരി എന്ന കടുംപിടുത്തത്തില് നിന്നു വളരെയധികം പിറകോട്ടു പോയിരിക്കുന്നു. പുതിയ ലിപി പ്രാവര്ത്തികമാകുന്നതിനു മുമ്പു തന്നെ (സത്യം പറഞ്ഞാല്, സംവൃതോകാരത്തെ പണ്ടു് എന്നു് എഴുതുന്നതിനു മുമ്പു തന്നെ) ചന്ദ്രക്കല മാത്രം ഉപയോഗിച്ചു സംവൃതോകാരം എഴുതിയിരുന്നു എന്ന അറിവും, ഇന്നുള്ള മലയാളപുസ്തകങ്ങളില് ഭൂരിപക്ഷവും ഉകാരത്തിന്റെ ചിഹ്നമില്ലാതെ ചന്ദ്രക്കല മാത്രമായാണു സംവൃതോകാരത്തെ എഴുതുന്നതു് എന്ന കണ്ടെത്തലുമാണു് ഇതിനു കാരണം.
ചുരുക്കം പറഞ്ഞാല് സംവൃതോകാരത്തെ ഉകാരത്തിന്റെ ചിഹ്നമില്ലാതെ ചന്ദ്രക്കല മാത്രം ഇട്ടു് (ഇട്ട് എന്ന്) എഴുതിത്തുടങ്ങിയതു പലരും പറയുന്നതു പോലെ പുതിയ ലിപി എഴുപതുകളില് പ്രാബല്യത്തില് വന്നപ്പോഴല്ല. അതൊരു തെറ്റാണെങ്കില് അതു തിരുത്താന് നാം വൈകിയതു മുപ്പത്തെട്ടു വര്ഷമല്ല, നൂറില് ചില്വാനം വര്ഷമാണു്.
മലയാളഭാഷ ഉപയോഗിക്കുന്ന ഭൂരിപക്ഷം എഴുത്തുകാരും അവലംബിക്കുന്ന ഒരു രീതി തെറ്റും പ്രാചീനവും നവീനവുമല്ലാത്ത ഇടയ്ക്കൊരു ചെറിയ കാലഘട്ടത്തില് മാത്രം (ഏകദേശം 70 വര്ഷം) കൂടുതല് പ്രാവര്ത്തികമായിരുന്നതുമായ ഒരു രീതി മാത്രം ശരിയും ആണു് എന്നു് ഈ അടുത്ത കാലത്തു വരെ ഞാനും ഇപ്പോഴും രചന, സ്വതന്ത്ര മലയാളം കമ്പ്യൂട്ടിംഗ് തുടങ്ങിയവരും ഉന്നയിക്കുന്ന വാദം വളരെ ബാലിശമാണു്. കഥകളുടെയും കവിതകളുടെയും മറ്റു പുസ്തകങ്ങളുടെയും കാര്യം അവിടെ നില്ക്കട്ടേ. മലയാളഭാഷയിലെ തെറ്റുകള് തിരുത്താനായി വളരെയധികം പുസ്തകങ്ങള് എഴുതിയിട്ടുള്ള പന്മന രാമചന്ദ്രന് നായരുടെ പുസ്തകങ്ങളിലും സംവൃതോകാരം ചന്ദ്രക്കല മാത്രമായാണു് അച്ചടിച്ചിരിക്കുന്നതു്. അതു തെറ്റാണെന്ന തോന്നല് അദ്ദേഹത്തിനുണ്ടായിരുന്നെങ്കില് അങ്ങനെ അച്ചടിച്ച ഒരു പുസ്തകം വെളിച്ചം കാണാന് അദ്ദേഹം സമ്മതിക്കില്ലായിരുന്നു.
ഇതും ആറ്റോമിക് ചില്ലുവാദവും തമ്മില് എന്തു ബന്ധം?
പണ്ടു്, വാക്കു്, തൈരു് തുടങ്ങിയ വാക്കുകളെ പണ്ട്, വാക്ക്, തൈര് എന്നിങ്ങനെയും എഴുതുന്നതു തെറ്റല്ല എന്ന വസ്തുതയാണു് അറ്റോമിക് ചില്ലുവാദികള്ക്കു് അനുകൂലമായ വസ്തുത.
ഇതനുസരിച്ചു്, അവനു് എന്ന വാക്കിനെ അവന് എന്നും എഴുതാം. നു് എന്നതു് ന + ഉ (ചിഹ്നം) + വിരാമം ആണു്. (യൂണിക്കോഡില് വിരാമം ഒരു വ്യഞ്ജനത്തിനു ശേഷം അതിലുള്ള സ്വരം കളയാന് മാത്രമാണുള്ളതു് എന്നൊരു വാദം വേറെ ഒരിടത്തു നടക്കുന്നുണ്ടു്. അവരാരും സംവൃതോകാരം എഴുതുന്ന രീതി കണ്ടിട്ടില്ലെന്നു തോന്നുന്നു.) ന് എന്നതു ന + വിരാമം എന്നും. ഇപ്പോള് ന് എന്ന ചില്ലക്ഷരം യൂണിക്കോഡില് എഴുതുന്നതു് ന + വിരാമം + ZWJ എന്നാണു്. മുന്പറഞ്ഞ പ്രകാരം ഇതിലെ ZWJ നഷ്ടപ്പെട്ടാല് ന് എന്ന ചില്ലക്ഷരം ന് എന്നാകും. അതായതു്, അവന് എന്നതിനും അവന് എന്നതിനും വ്യത്യാസമില്ലാതെ പോകും. ഇതു് അനുവദിക്കാന് സാദ്ധ്യമല്ല. ഇതു മുകളില്പ്പറഞ്ഞ സഭംഗശ്ലേഷമല്ല.
അവന്/അവനു് എന്നതു് ഒരുദാഹരണം മാത്രം. ഇതുപോലെ ചിന്താക്കുഴപ്പത്തിനു വഴി തെളിക്കുന്ന അനേകം വാക്കുകള് മലയാളത്തിലുണ്ടു്. ഈ ചിന്താക്കുഴപ്പം ഒഴിവാക്കേണ്ടതുണ്ടു്.
എന്താണു അറ്റോമിക് ചില്ലുവാദികള് പറയുന്നതു്?
ചില്ലക്ഷരങ്ങളെ മൂലവ്യഞ്ജനം + വിരാമം + ZWJ എന്നല്ലാതെ ഒരു പ്രത്യേക കോഡു കൊണ്ടു സൂചിപ്പിക്കുക. അപ്പോള് ഒരിക്കലും ഒന്നു മറ്റേതാകുന്ന പ്രശ്നം ഉണ്ടാവില്ല. ഏതു ബ്രൌസറിലും ഓപ്പറേറ്റിംഗ് സിസ്റ്റത്തിലും ചില്ലക്ഷരങ്ങള് കാണാന് കഴിയും.
എന്റെ അഭിപ്രായം:
മുകളില്പ്പറഞ്ഞ കാരണങ്ങള് കൊണ്ടു് എനിക്കു് ഇപ്പോള് അറ്റോമിക് ചില്ലുകള് വേണം എന്ന വാദത്തിനോടാണു യോജിപ്പു്. അതിനെ എതിര്ക്കുന്ന യുക്തിയുക്തമായ വാദം കേട്ടാല് ഈ അഭിപ്രായം തിരുത്താന് ഞാന് തയ്യാറാണു്. പക്ഷേ, ആ വാദം “അവനു് എന്നതിനെ അവന് എന്നെഴുതുന്നതു തെറ്റാണു്” എന്നതാവരുതു് എന്നു മാത്രം.
വാല്ക്കഷണം
ഇതു ഫയര് ഫോക്സ് 2-വില് വായിക്കുന്നവര് ചില്ലായ ന്, ചില്ലല്ലാത്ത ന് എന്നിവ ഒരുപോലെ കണ്ടു് അന്തം വിട്ടിരിക്കുന്നുണ്ടാവാം. അവര് ഈ പോസ്റ്റിന്റെ ആദിയിലുള്ള മൈക്ക് ടെസ്റ്റിംഗ് ഒന്നു കൂടി വായിക്കുക.
അറ്റോമിക് ചില്ലുണ്ടായിരുന്നെങ്കില് ഈ കുഴപ്പമൊന്നുമുണ്ടാവില്ലായിരുന്നു. ഭാവിയിലെങ്കിലും ബ്ലോഗ് വായനക്കാര്ക്കു് ഈ പ്രശ്നമുണ്ടാവില്ല എന്നു പ്രത്യാശിക്കാം.
ഇതിന്റെ ചില കമന്റുകള്ക്കു മറുപടി:
[2008-02-05]
സുരേഷ് (സുറുമ?) ഈ കമന്റില് ഇങ്ങനെ പറയുന്നു:
പ്രചാരം കൂടുതലാണു് എന്നതുകൊണ്ടുമാത്രമായിരിക്കും ഉദാഹരിക്കാന് ഉമേഷ് ഗൂഗ്ള് തെരെഞ്ഞെടുത്തതു് എന്നു കരുതുന്നു 🙂 .സ്വതന്ത്രസോഫ്റ്റ്വെയന് ആയ ബീഗ്ള് GNU/Linux സിസ്റ്റങ്ങളില് ഡെസ്ക്ടോപ് സെര്ച്ചിനു് ഉപയോഗിച്ചുപോരുന്നുണ്ടു്.അതുപയോഗിച്ചു് നടത്തിയ തെരച്ചിലിന്റെ പടം കൂടി ഒന്നിടണമെന്നു് അഭ്യര്ത്ഥിക്കുന്നു.ഒന്നും വേണ്ട, യാഹൂ,msn എന്നിയും ഇതുപോലുള്ള ഫലമാണോ തരുന്നതു് എന്നുകൂടി വ്യക്തമാക്കൂ.
അതായതു്, ഇതു് ഗൂഗിളിലെ ഒരു ബഗ്ഗാണെന്നു്, അല്ലേ? ഇനി, ഈ പോസ്റ്റെഴുതാന് വേണ്ടി ഞാന് ഗൂഗിള് കോഡില് കയറി ഈ ബഗ് അവിടെ ഉണ്ടാക്കി എന്നു പറയില്ലല്ലോ, അല്ലേ? (തമാശയല്ല, ജീമെയിലില് ജോയിനര് കളയുന്നതു സിബു മനഃപൂര്വ്വം ഉണ്ടാക്കിയ ഒരു ബഗ് ആണെന്നു് അനിവറാണെന്നു തോന്നുന്നു ഒരിക്കല് പറഞ്ഞിരുന്നു :))
ഇനി, യാഹൂ, എം. എസ്. എന്. എന്നിവയ്ക്കു് ഈ കുഴപ്പമില്ല എന്ന വാദത്തെപ്പറ്റി, ദാ അവ താഴെ. മറ്റുള്ള കാര്യങ്ങള്ക്കു വ്യത്യാസമില്ല. വിന്ഡോസ് എക്സ്. പി., ഇന്റര്നെറ്റ് എക്സ്പ്ലോറര്, കാര്ത്തിക ഫോണ്ട്.
ആദ്യമായി, അതേ സേര്ച്ച് യാഹൂ ഉപയോഗിച്ചു്:
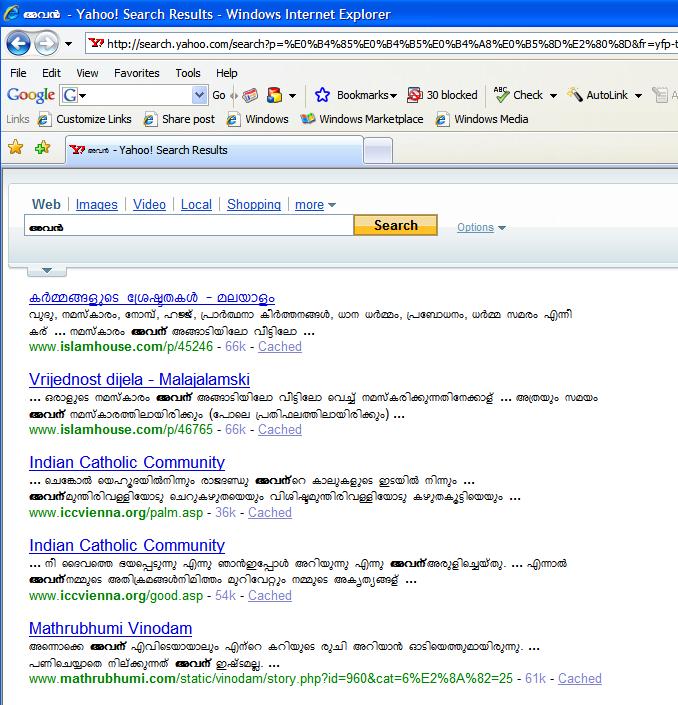
അവനെയും അവനെയും കണ്ടല്ലോ? യാഹുവിന്റെ അവന് ഗൂഗിളിന്റെ അവനുമായി വ്യത്യാസമൊന്നുമില്ല എന്നും കണ്ടല്ലോ?
ഇനി, അതു തന്നെ എം. എസ്. എന്. ലൈവ് സേര്ച്ച് ഉപയോഗിച്ചു്:
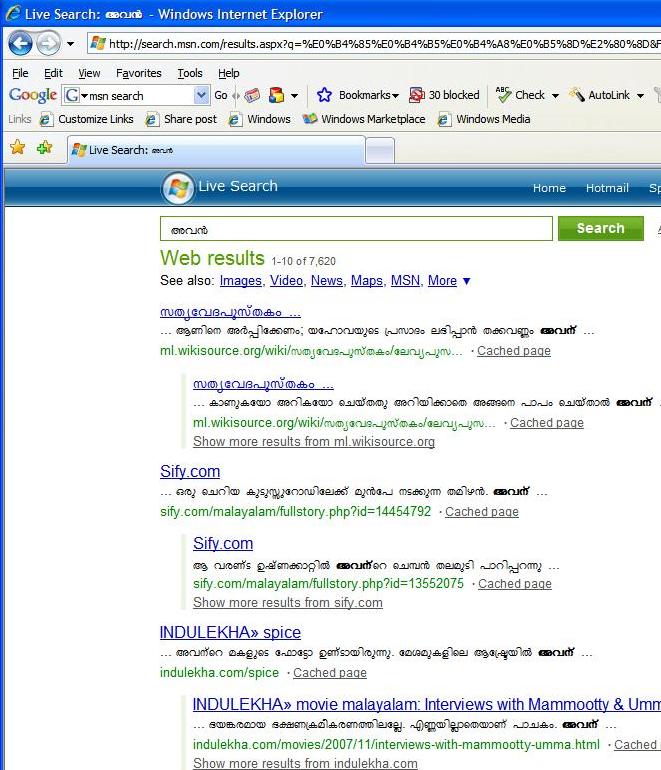
ക്ഷമിക്കണം, ബീഗിള് ഇപ്പോള് കൈവശമില്ല. ഇനി അതില് ജോയിനര് കളയുന്നില്ല എന്നതു കൊണ്ടു് ഞാന് പറഞ്ഞതു കൊണ്ടു വ്യത്യാസമൊന്നും വരാനില്ല. ജോയിനറുകള് എപ്പോഴും നഷ്ടപ്പെടും എന്നു ഞാന് പറഞ്ഞില്ല, നഷ്ടപ്പെട്ടേയ്ക്കാം എന്നേ പറഞ്ഞുള്ളൂ.
ഇനി മുതല്, ദയവായി ആരോപണം ഉന്നയിക്കുന്നതിനു മുമ്പു് അതൊന്നു പരീക്ഷിച്ചു നോക്കുന്നതു നന്നായിരിക്കും. ഓരോന്നും പരീക്ഷിച്ചു നോക്കി സ്ക്രീന്ഷോട്ടെടുത്തു് അപ്ലോഡു ചെയ്തു പോസ്റ്റു തിരുത്താന് അല്പം ബുദ്ധിമുട്ടാണേ, അതുകൊണ്ടാണു് 🙂
[2008-02-13]
ഗൂഗിള്, യാഹൂ, ലൈവ് സേര്ച്ച്, വെബ് ദുനിയാ എന്നീ സേര്ച്ച് എഞ്ചിനുകള് ജോയിനറുകളെ കൈകാര്യം ചെയ്യുന്നതിനെപ്പറ്റി കമന്റുകള് ഉണ്ടായിരുന്നു. ഞാന് കണ്ടെത്തിയതു താഴെ:
Xഅവന്Y എന്നതു് (X, Y എന്നിവ ഏതെങ്കിലും ഫോര്മാറ്റ് സ്ട്രിംഗുകള്) ചില്ലോടെ കാണണമെങ്കില് X-അ-വ-ന-വിരാമം-ZWJ-Y എന്നിവ ഉണ്ടാവണം. അതായതു്, U+0D05 U+0D35 U+0D28 U+0D4D U+200D എന്നീ കോഡ്പോയിന്റുകള് ഫോര്മാറ്റിംഗ് കാരക്ടേഴ്സ് ആയ X, Y എന്നിവയ്ക്കു് ഇടയില് വരണം.
ഗൂഗിള് സേര്ച്ച് റിസല്റ്റുകള് കാണിക്കുന്ന പേജില് ZWJ-യെ ഒഴിവാക്കുന്നു. <b->-അ-വ-ന-വിരാമം-<-/-b-> (U+003C U+0062 U+003E U+0D05 U+0D35 U+0D28 U+0D4D U+003C U+002F U+0062 U+003E) എന്നേ ഉള്ളൂ. ZWJ (U+200D)-യെ ഒഴിവാക്കി.
യാഹൂ ZWJ കളയുന്നില്ല. പക്ഷേ, അവന് എന്നതു കാണിക്കുമ്പോള് <b->-അ-വ-ന-വിരാമം-ZWJ-<-/-b-> (U+003C U+0062 U+003E U+0D05 U+0D35 U+0D28 U+0D4D U+200D U+003C U+002F U+0062 U+003E) എന്നതിനു പകരം <b->-അ-വ-ന-വിരാമം-<-/-b->-ZWJ (U+003C U+0062 U+003E U+0D05 U+0D35 U+0D28 U+0D4D U+003C U+002F U+0062 U+003E U+200D) എന്നു കാണിക്കുന്നു. (അതായതു്, </b>-നെ ZWJ-നു ശേഷം ചേര്ക്കുന്നതിനു പകരം മുമ്പു ചേര്ക്കുന്നു.) അതു കൊണ്ടാണു് ബ്രൌസറില് ചില്ലക്ഷരം കാണാത്തതു്.
മൈക്രോസോഫ്റ്റ് ലൈവ് സേര്ച്ച് ചിലയിടത്തു യാഹൂ ചെയ്തതു പോലെ ചെയ്യുന്നു. മറ്റു ചിലടത്തു് ZWJ-യെ ZWNJ ആക്കുന്നുമുണ്ടു്. എന്തായാലും ജോയിനര് കളയുന്നില്ല എന്നു തോന്നുന്നു.
വെബ്ദുനിയാ ഒരു കുഴപ്പവും ഇല്ലാതെ ഇതു കൈകാര്യം ചെയ്യുന്നു. ZWJ-യെ കളയുന്നുമില്ല, അ-വ-ന-വിരാമം-ZWJ- എന്നു തന്നെ കാണിക്കുകയും ചെയ്യുന്നു. അതുകൊണ്ടു ചില്ലക്ഷരങ്ങള് ഹൈലൈറ്റു ചെയ്തു കാണാം. (എന്നു് എനിക്കു തോന്നി. കൂടുതല് താഴെ വായിക്കുക.)
ഇതില് നിന്നു് മലയാളത്തോടു് ഏറ്റവും നീതി പുലര്ത്തുന്നതു വെബ് ദുനിയാ ആണെന്നും, ഏറ്റവും മോശമായി മലയാളം സേര്ച്ചു ചെയ്യുന്നതു ഗൂഗിള് ആണെന്നും പറയാമോ?
വരട്ടേ. സ്വപ്നം (U+0D38 U+0D4D U+0D35 U+0D2A U+0D4D U+0D28 U+0D02) എന്നും സ്വപ്നം (U+0D38 U+0D4D U+0D35 U+0D2A U+0D4D U+200C U+0D28 U+0D02) എന്നും ഒന്നു സേര്ച്ചു ചെയ്തു നോക്കൂ. ഇവ തമ്മിലുള്ള വ്യത്യാസം പ, ന എന്നിവയെ വേര്തിരിച്ചു കാണിക്കാന് ഒരു ZWNJ ഇട്ടിട്ടുണ്ടു് എന്നു മാത്രമാണു്.
| സേര്ച്ച് എഞ്ചിന് | സ്വപ്നം ഫലങ്ങള് | സ്വപ്നം ഫലങ്ങള് |
| ഗൂഗിള് | 13200 | 13200 |
| യാഹൂ | 3270 | 445 |
| ലൈവ് സേര്ച്ച് | 221 | 65 |
| വെബ് ദുനിയാ | 104 | 104 |
യാഹൂവും ലൈവ് സേര്ച്ചും ജോയിനര് ഉള്ളതും ഇല്ലാത്തതും രണ്ടായി കണ്ടിട്ടു് രണ്ടു ഫലങ്ങള് തരുന്നു. ഗൂഗിളും വെബ്ദുനിയയും ഒരേ ഫലങ്ങളും. (ഗൂഗിള് കൂടുതല് ഫലങ്ങള് തരുന്നു എന്നതു് ഇവിടെ പ്രസക്തമല്ല.)
വെബ് ദുനിയയെപ്പറ്റിയുള്ള എന്റെ അഭിപ്രായം പിന്നെയും കൂടി. കൊള്ളാമല്ലോ, മലയാളത്തിനു പറ്റിയ സേര്ച്ച് എഞ്ചിന് തന്നെ!
പിന്നെ, നമ്മുടെ പഴയ അവനവന് കടമ്പ (പ്രയൊഗത്തിനു കടപ്പാടു് സുറുമയ്ക്കു്) തന്നെ ഒന്നു സേര്ച്ചു ചെയ്തു നോക്കി.
അവന് എന്നതു് വെബ്ദുനിയായില് സേര്ച്ചു ചെയ്തതു് ഇവിടെ:
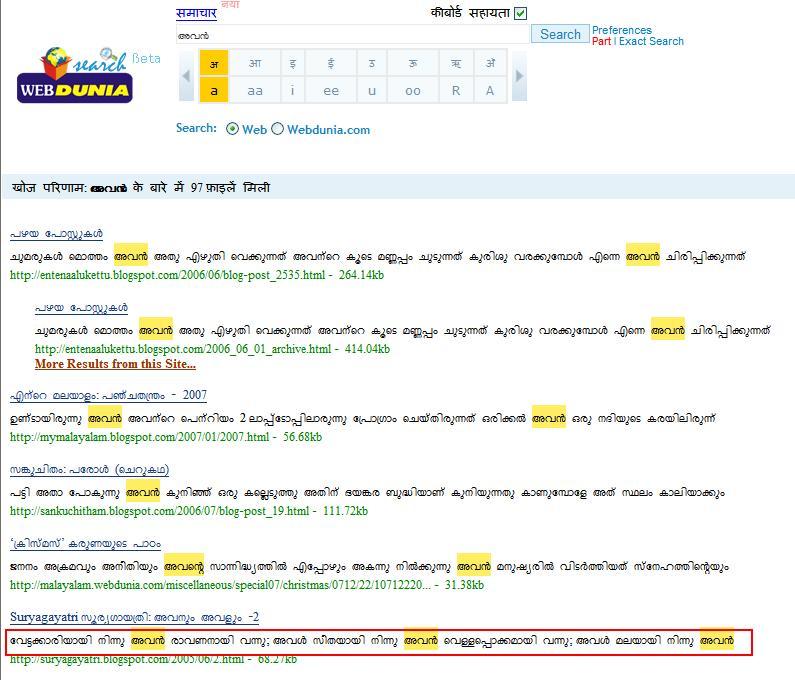
അവന് എന്നതു വെബ്ദുനിയായില് സേര്ച്ചു ചെയ്തതു് ഇവിടെ.
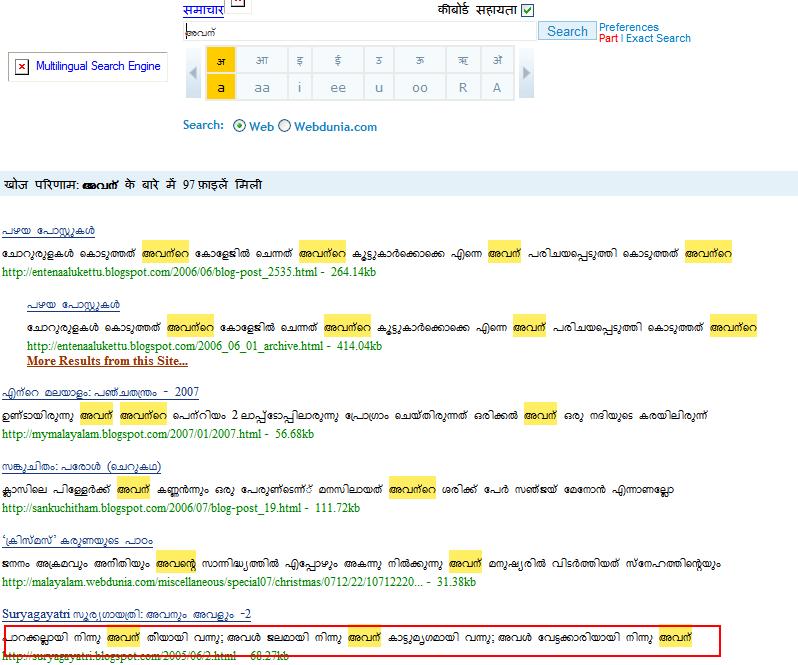
ഇവ രണ്ടിലും വന്നിട്ടുള്ള സൂര്യഗായത്രി പോസ്റ്റിന്റെ ഫലം ശ്രദ്ധിക്കുക. (ചുവന്ന ചതുരത്തില് കാണിച്ചിട്ടുണ്ടു്) ഒരേ പോസ്റ്റിനെ രണ്ടു വാക്കുകള് കൊണ്ടു സേര്ച്ചു ചെയ്തപ്പോള് കാണിക്കുന്നതു വ്യത്യസ്തമായാണു് എന്നു കാണാം. ഇതെങ്ങനെ സംഭവിച്ചു? സൂര്യഗായത്രിയുടെ പോസ്റ്റില് പോയി നോക്കിയാല് “അവന്” എന്നാണെന്നു കാണാം. പിന്നെങ്ങനെ വെബ് ദുനിയാ “അവന്” എന്നു കാണിച്ചു?
ആകെ സംശയമായി. വെബ് ദുനിയാ നമ്മള് സേര്ച്ചു ചെയ്ത പദം ഈ പേജില് മാറ്റി വെയ്ക്കുന്നുണ്ടോ?
കൂടുതല് നോക്കിയപ്പോള് കാരണം വ്യക്തമായി. വെബ് ദുനിയാ ചെയ്യുന്നതു Partial search ആണു്. അവന് എന്നതു് അവന് + ZWJ ആയതിനാല് അതും ഫലത്തില് വന്നു എന്നു മാത്രം.
എങ്കിലും ജോയിനറുകളെ ഒഴിവാക്കിയാണു വെബ് ദുനിയായും സേര്ച്ചു ചെയ്യുന്നതു് എന്നു കാണാന് കഴിയും. കണ്മണി, കണ്മണി, കണ്മണി എന്നിവ ഒരേ എണ്ണം ഫലങ്ങളാണു തരുന്നതു്. അതു പോലെ വെണ്മ, വെണ്മ, വെണ്മ എന്നിവയും. യാഹുവും ലൈവ് സേര്ച്ചും ഇവയ്ക്കു് വ്യത്യസ്ത എണ്ണം ഫലങ്ങളാണു തരുന്നതു്.
ഇതു പൂര്ണ്ണമായും ശരിയാണോ എന്നു പറയാന് കഴിയില്ല. വെബ് ദുനിയായുടെ സേര്ച്ച് അല്പം കൂടി intelligent ആയതിനാലാവാം. ഒന്നിനെ സേര്ച്ചു ചെയ്യുമ്പോള് മറ്റു പലതും കൂടി ഉള്ക്കൊള്ളിക്കുന്ന രീതി ഒരു പക്ഷേ മലയാളത്തിനു വേണ്ടി വളരെ നന്നാക്കിയതാവാം. എങ്കിലും കണ്മണി, കണ്മണി എന്നിവ തിരഞ്ഞപ്പോള് എനിക്കു് ഈ പേജു കിട്ടി. ഇതില് കണ്മണി ഇല്ല. കണ്ണും വെണ്മണിയും ഉണ്ടു്.
വെബ് ദുനിയാ തികച്ചും ഒരു വ്യത്യസ്ത സേര്ച്ച് എഞ്ചിന് ആണെന്നേ എനിക്കു പറയാന് പറ്റുന്നുള്ളൂ 🙂
യാഹുവും ലൈവ് സേര്ച്ചും ജോയിനര് കളയാതെ സേര്ച്ചു ചെയ്യുന്നു. അവന്/അവന് എന്ന കാര്യത്തില് ചില്ലിന്റെ ഇപ്പോഴത്തെ വികലമായ എന്കോഡിംഗ് മൂലം അതു നന്നായി ഭവിക്കുന്നു. എന്നാല് സ്വപ്നം/സ്വപ്നം തുടങ്ങിയവയില് അതു് ആവശ്യത്തിനു ഫലങ്ങള് തരുന്നുമില്ല.
ഗൂഗിളിനെ ന്യായീകരിക്കാനോ അവരുടെ പരസ്യത്തിനു വേണ്ടിയോ അല്ല ഇതെഴുതിയതു്. ജോയിനറുകള് കളഞ്ഞു സേര്ച്ചു ചെയ്തതിനു് അവര്ക്കു് അതിന്റേതായ കാരണങ്ങള് ഉണ്ടാവും എന്നു കാണിക്കാന് ആണു്. ഇങ്ങനെ ജോയിനര് വേണ്ടെന്നു വെയ്ക്കാന് യൂണിക്കോഡ് സ്റ്റാന്ഡേര്ഡ് എതിരുമല്ല.
പിന്നെ, ചില ആപ്ലിക്കേഷനുകള് ജോയിനറുകളെ കണക്കാക്കാതെ ഇരുന്നേക്കാം എന്നു കാണിക്കാനായി മാത്രമായിരുന്നു ആ ഉദാഹരണം. ഗൂഗിളും വെബ് ദുനിയായും ജോയിനറുകളെ കണക്കാക്കുന്നില്ല എന്നും നാം കണ്ടു. യാഹുവും ലൈവ് സേര്ച്ചും ജോയിനര് കളയുന്നില്ല. അവ കളയുന്നുണ്ടെന്നു ഞാന് തെറ്റായി പറഞ്ഞതു് അവര് അതു ഹൈലൈറ്റു ചെയ്യുന്നതിലെ അപാകത കൊണ്ടായിരുന്നു. (ചൂണ്ടിക്കാട്ടിയ റാല്മിനോവിനു നന്ദി.) ഈ പോസ്റ്റിന്റെ ഉദ്ദേശ്യം ഏതൊക്കെ ആപ്ലിക്കേഷനുകള് എന്തൊക്കെ ചെയ്യുന്നു, ഏതിലൊക്കെ ബഗ്ഗുകളുണ്ടു് എന്നുള്ളതല്ല, മറിച്ചു് ജോയിനറുകളില് മാത്രമുള്ള വ്യത്യാസം ഗണ്യമാകത്തക്ക വിധത്തില് അവയെ ഉപയോഗിക്കാമോ എന്നതാണു്. നമുക്കു വിഷയത്തിലേക്കു വരാം.

സന്തോഷ് തോട്ടിങ്ങല് | 05-Feb-08 at 4:21 am | Permalink
ഉമേഷ്ജി, യൂണിക്കോഡിന്റെ ഇന്ഡിക് മെയിലിങ്ങ് ലിസ്റ്റിലുണ്ടായിരുന്നോ എന്നറിയില്ല. അവിടെ ഈ പ്രശ്നങ്ങളൊക്കെ ചര്ച്ച ചെയ്തിരുന്നു. ഇതു വായിക്കുന്നവര്ക്ക് അനുബന്ധമായി ആ ചര്ച്ചകളും വായിക്കാവുന്നതാണു്.
http://www.unicode.org/~ecartis/indic/indic.2008-01 ,
http://www.unicode.org/~ecartis/indic/indic.2008-02 എന്നീ പേജുകളിലെ ചര്ച്ചകള് വായിക്കാവുന്നതാണു്. New Malayalam codepoints എന്ന സബ്ജക്ടിലെ മെയിലുകളാണു് വായിക്കേണ്ടതു്. യൂസര്നെയിമും പാസ്സ്വേഡും ചോദിക്കുമ്പോള് കൊടുക്കേണ്ടതു് ഇതാണു്. Username: unicode-ml password: unicode
സ്വതന്ത്ര മലയാളം കമ്പ്യൂട്ടിങ്ങ് ആണവചില്ലിനെതിരെ UTC യ്ക്കു് സമര്പ്പിച്ച വാദങ്ങളും വായിക്കുക. http://images.wikia.com/fci/images/2/23/SMC_Unicode_5.1.pdf
ഇനി സെര്ച്ച് റിസള്ട്ടുകള് ചില്ലുകളയുന്നു എന്നു പറഞ്ഞല്ലോ. ഇതിനെപ്പറ്റിയുള്ള ചര്ച്ചക്കിടയില് James Kass എന്നൊരാള് പറഞ്ഞതു താഴെക്കൊടുക്കുന്നു.
“Let’s suppose you are involved with a hypothetical search engine
company called “DataQuest” and, for one reason or another, decide
to research the frequency of web pages which offer text in the
fictional Klingon language/script using the ConScript Unicode
Registry’s Private Use Area Unicode encoding.
You might proceed by entering some common words into the
search box of your engine. If your engine restricts P.U.A. characters,
or maps them all to zero, your search results would be nothing.
However, since you pulled those common words from a web page
in the first place, you know that such pages exist. Would this
be a good indication that it is time to change the settings? Or
would it be better to encode Klingon in TUS? (smile)
If that hypothetical situation is too far-fetched, suppose you
are working for a real company and Malayalee users were complaining
about search results being too fuzzy because your collation interface
was stripping certain characters for comparison purposes.”
ഉമേഷ്ജീ, ലേഖനം മുഴുവനായില്ലല്ലോ? Canonical equivalence, How to handle existing text etc…
Aravind | 05-Feb-08 at 6:07 am | Permalink
ഹും….ദീര്ഘനിശ്വാസം.
എന്തരോ എന്തോ…
തര്ക്കത്തിന് തീരുമാനമാവാന് വോട്ട് വേണങ്കില് പറേണേ ഉമേഷ്ജി, പറയുന്നിടത്ത് കുത്താം..
ഈ പരിപാടിയില് എന്നെക്കൊണ്ട് അത്രയൊക്കേ പറ്റൂ. ഹല്ല പിന്നെ.
Aravind | 05-Feb-08 at 6:33 am | Permalink
പ്ലീസ് നോട്ട് : ഞാന് മുന്പിട്ട കമന്റിലെ ഈ വിഷയത്തിലെ നിസ്സഹായത എന്റെ അതി കഠിനമായ സമയക്കുറവ് മൂലം മാത്രമാണെന്നും, ബുദ്ധിപരമോ ഭാഷാജ്ഞാനപരമൊ ആയ യാതൊരു പരിമിതികളും കൊണ്ടല്ലെന്നും എല്ലാവരേയും വീണ്ടും വീണ്ടും ഓര്മിപ്പിക്കുകയാണ്.
ആരും തെറ്റിദ്ധരിക്കല്ലേ…….
😉
കണ്ണൂരാന് | 05-Feb-08 at 7:07 am | Permalink
കുറെക്കാലമായി ഈ കോണ്ടസയുടെ പിന്നാലെ നടക്കുന്നു. ഇപ്പോഴാ വല്ലതുമൊക്കെ മനസ്സിലായത്. നന്ദി ഉമേഷ്ജി.
സിബു | 05-Feb-08 at 8:20 am | Permalink
സത്യത്തില് ആ ജെയിംസ് സായ്വെന്താണ് പറയുന്നത് എന്ന് മനസ്സിലായില്ല. എന്കോഡിംഗിന് എന്തു പ്രശ്നങ്ങളുണ്ടെങ്കിലും കമ്പനികള് അതിന് എന്തെങ്കിലും വര്ക്കെറൌണ്ട് കണ്ടുപിടിക്കുമെന്നോ.. ആയിരിക്കാം. അതുകൊണ്ട് എന്കോഡിംഗിന്റെ പ്രശ്നം പ്രശ്നമല്ലാതാവുമോ? അങ്ങനെയാണെങ്കില് യുണീക്കോഡ് തന്നെ ആവശ്യമില്ലായിരുന്നല്ലോ. നമുക്ക് ദീപികയും മനോരമയും ഒക്കെ ആയിത്തന്നെ പോകാമായിരുന്നു. കമ്പനികള് ആ സൈറ്റുകള് സെര്ച്ച് ചെയ്യാനും എന്തെങ്കിലും വഴികള് കണ്ടുപിടിക്കുമായിരുന്നല്ലോ.
സ്റ്റാന്റേഡെന്നാല് കുറേ എക്സപ്ഷന്സല്ലല്ലോ.. എല്ലാത്തിന്റേയും കണ്സപ്റ്റിലും സ്പെക്സിലും ഉള്ള ഏകീകരണമല്ലേ. എക്സപ്ഷന്സുകൊണ്ട് മലയാളത്തെ ഏച്ചുകെട്ടാനാണെങ്കില് ഇപ്പോള് പറഞ്ഞ ഫോണ്ട് എന്കോഡിംഗുകള് അതാണല്ലോ ചെയ്യുന്നത് – എക്സപ്ഷനുകളുടെ എക്സ്റ്റ്രീം.
പ്രവീണ് | 05-Feb-08 at 9:07 am | Permalink
ഉമേഷ്ജി ഒരു കാര്യം മാത്രം ചോദിച്ചോട്ടെ. ഈ ZWJ, ZWNJ എന്നീ അക്ഷരങ്ങെന്തിനാണെന്നാലോചിച്ചിട്ടുണ്ടോ? കാഴ്ചയില് വ്യത്യാസമുണ്ടാക്കാന്. അപ്പോള് കാണിയ്ക്കുമ്പോള് അവ ഒഴിവാക്കുന്നതു് യൂണികോഡിന്റെ പ്രശ്നമാണോ? യൂണികോഡ് പ്രയോഗത്തില് വരുത്താനറിയാത്തവര്ക്കു് വേണ്ടിയാണോ നമ്മള് യൂണികോഡ് മാറ്റേണ്ടതു്? അവന്/അവന് എന്നിവയില് അകരാദിക്രമത്തിലേതു് വേണമെങ്കിലും മുന്നില് വരാം എന്നും മാത്രമേ അവയ്ക്കു് കൊളേഷന് വെയിറ്റില്ല എന്നതിനര്ത്ഥം. കാണിയ്ക്കുമ്പോള് തീര്ച്ചയായും അവ ഒഴിവാക്കാന് പറ്റില്ല.
വിശദമായി പിന്നീടെഴുതാം.
Moorthy | 05-Feb-08 at 11:20 am | Permalink
കമന്റുകള് മെയിലില് കിട്ടാന് ഇത്…
Priya Unnikrishnan | 05-Feb-08 at 2:07 pm | Permalink
അപ്പൊ അതാണല്ലേ ഈ കോണ്ടസാ കോണ്ടസാ
suresh | 05-Feb-08 at 2:11 pm | Permalink
സിബു:
“സ്റ്റാന്റേഡെന്നാല് കുറേ എക്സപ്ഷന്സല്ലല്ലോ.. എല്ലാത്തിന്റേയും കണ്സപ്റ്റിലും സ്പെക്സിലും ഉള്ള ഏകീകരണമല്ലേ.”
ഭാഷയില് നിലനില്ക്കുന്ന exceptions മാറ്റുന്നതു് യൂണിക്കോഡിന്റെ തലവേദനയല്ല.അവ എല്ലാ ഭാഷകളിലും ഉള്ളതുതന്നെയാണു്.
ഉമേഷ് പറഞ്ഞ അവന്/അവനു് വ്യവഛേദനത്തിന്റെ കാര്യം:
ഉദാഹരണത്തിനു് “ന്'” എന്നതിനു് രണ്ടു രീതിലും ഉച്ചാരണം ആവാം;ചില്ലായിട്ടും സംവൃതോകാരമായിട്ടും.അവയെ വേര്തിരിച്ചു് കാണിക്കാനും സംവിധാനം നിലവിലുണ്ടു്.”ന്” എന്നു രേഖപ്പെടുത്തിയാല് ചില്ലായി;”നു്” എന്നായാല് സംവൃതോകാരവുമായി.
ഇനി ആണവ”ന്” വരുകയാണെന്നു കരുതുക. പദമധ്യേ ഇവന് പ്രശ്നക്കാരനാകും.ഉദാ:വാല്മീകി/വാല്മീകി, കല്ക്കത്ത/കല്ക്കത്ത തുടങ്ങിയവ.തിരച്ചിലില് ഇതു പ്രശ്നമാകും.ഉച്ചാരണം,അര്ത്ഥം,നിഷ്പത്തി,അക്ഷരവിന്യാസം എന്നിയിലൊന്നും യാതൊരും ഭേദവും ഇല്ലാതെ കേവലം എഴുത്തുരീതിയില് മാത്രം വ്യത്യാസം പ്രകടമാക്കുന്നു എന്ന ഒറ്റ കാരണം കൊണ്ടു് ഇത്തരം വാക്കുകളെ വേര്തിരിക്കുന്നതു് മലയാളത്തിനു യോജിച്ചരീതിയാണോ എന്നുകൂടി പറയുക.
ZWJ-നെ ഒഴിവാക്കിയതുകൊണ്ടുമാത്രമാണു് മേല്പറഞ്ഞ പ്രശ്നം ഗൂഗ്ള് കാണിച്ചതു്.
പ്രചാരം കൂടുതലാണു് എന്നതുകൊണ്ടുമാത്രമായിരിക്കും ഉദാഹരിക്കാന് ഉമേഷ് ഗൂഗ്ള് തെരെഞ്ഞെടുത്തതു് എന്നു കരുതുന്നു :).സ്വതന്ത്രസോഫ്റ്റ്വെയന് ആയ ബീഗ്ള് GNU/Linux സിസ്റ്റങ്ങളില് ഡെസ്ക്ടോപ് സെര്ച്ചിനു് ഉപയോഗിച്ചുപോരുന്നുണ്ടു്.അതുപയോഗിച്ചു് നടത്തിയ തെരച്ചിലിന്റെ പടം കൂടി ഒന്നിടണമെന്നു് അഭ്യര്ത്ഥിക്കുന്നു.ഒന്നും വേണ്ട, യാഹൂ,msn എന്നിയും ഇതുപോലുള്ള ഫലമാണോ തരുന്നതു് എന്നുകൂടി വ്യക്തമാക്കൂ.
-സുരേഷ്
Umesh:ഉമേഷ് | 05-Feb-08 at 3:16 pm | Permalink
ആഹാ, ചില്ലുവാദികളും ചില്ലുവിരോധികളും എത്തിയിട്ടുണ്ടല്ലോ!
സംവാദങ്ങള് സ്വാഗതം ചെയ്യുന്നു. പക്ഷേ ഇതു് ഇന്ഡിക് ലിസ്റ്റു പോലെ തെറിവിളിയും വ്യക്തിഹത്യയുമായാല് ആ കമന്റുകള് ഞാന് ഡിലീറ്റ് ചെയ്യും എന്നു നേരത്തേ പറയുന്നു.
സന്തോഷ്, ഇന്ഡിക് ലിസ്റ്റു ഞാന് പണ്ടേ കാണാറുണ്ടു്. ചില്ലുകളെപ്പറ്റി ആദ്യം സംവാദം നടന്നപ്പോള് മുതല്. രചന അക്ഷരവേദി ആദ്യം ഒരു സൂപ്പര് സീക്രട്ട് ഡോക്യുമെന്റ് ഇറക്കി “യൂട്ടീസി അല്ലാതെ നീയൊന്നും ഇത്ര മഹത്തായ സാധനം കാണണ്ടാ” എന്നു പറഞ്ഞു പൂഴ്ത്തി വെച്ച കാലത്തും. സന്തോഷ് പറയുന്നതു് 2008-ലെ കാര്യമല്ലേ? അതും കണ്ടിരുന്നു, ജെയിംസ് കാസ്സിന്റെ മെയിലുകളും. ബൂലോഗത്തിലെ മലയാളം തെറികള് കേട്ടു മടുക്കുമ്പോള് ചിലപ്പോള് ഇന്ഡിക് ലിസ്റ്റില് പോകാറുണ്ടു്, ഇംഗ്ലീഷ് തെറികള് കേള്ക്കാന് 🙂
സന്തോഷ്, പ്രവീണ്, സിബു, സുരേഷ് തുടങ്ങിയവര്ക്കു് ഇനിയും പറയാന് എന്തുണ്ടെന്നു നോക്കട്ടേ. മറുപടി ഒന്നിച്ചു പറയാം.
സുരേഷിന്റെ കമന്റില് ജോയിനര് കളയുന്ന ഒരേയൊരു സേര്ച്ച് എഞ്ചിന് ഗൂഗിളാണെന്നും യാഹൂ, എം. എസ്. എന്. തുടങ്ങിയവ അതു ചെയ്യുന്നില്ലെന്നും കണ്ടു. കൂടാതെ ഞാന് ഗൂഗിളില് സേര്ച്ച് ചെയ്യുന്നതിനെപ്പറ്റി ഒരു കുത്തുവാക്കും. യാഹുവിലും എം. എസ്. എന്നിലും സേര്ച്ചു ചെയ്തതിന്റെ സ്ക്രീന് ഷോട്ടുകളും ചേര്ത്തിട്ടുണ്ടു്. കാണുക, ആനന്ദതുന്ദിലരാകുക.
അരവിന്ദോ,
ഇവിടെ വോട്ടും ശക്തിപ്രകടനവും പെറ്റീഷന് അയയ്ക്കലും ഒന്നുമില്ല. ഞാന് പറയുന്നതു വെള്ളം തൊടാതെ വിഴുങ്ങുകയും വേണ്ടാ. അടുത്ത കാലത്തെ ചില പോസ്റ്റുകള് കണ്ടാല് അറ്റോമിക് ചില്ലുകള് എന്തോ മലയാളഭാഷയെ കൊന്നു കൊലവിളിക്കുന്ന ഒരു സാധനമാണെന്നു തോന്നുമായിരുന്നു. എന്താണു സാധനം എന്നു രണ്ടു പക്ഷവും പറയുന്ന (അവസാനം എന്റെ അഭിപ്രായവും) ഒരു പോസ്റ്റെന്നു മാത്രമേ ഉദ്ദേശിച്ചിട്ടുള്ളൂ.
മൂര്ത്തീ,
ഈ ബ്ലോഗ് തുടങ്ങിയപ്പോള് മുതല് ഈ കമന്റ് സബ്സ്ക്രിപ്ഷന് ഞാന് ഇതില് ഇട്ടിട്ടുണ്ടായിരുന്നു. അതു വര്ക്കു ചെയ്യുന്നുണ്ടല്ലേ? സന്തോഷം!
എല്ലാവര്ക്കും നന്ദി.
suresh | 05-Feb-08 at 4:42 pm | Permalink
‘യാഹൂ’വില് സെര്ച്ചു് ഫലം ഇവിടെ => http://surumafonts.googlepages.com/yahoo-search.jpeg
‘msn’-ല് സെര്ച്ചു് ഫലം ഇവിടെ => http://surumafonts.googlepages.com/msn-search.jpeg
രണ്ടും Iceweasel-2.0.0.11 (read Firefox) നല്കിയതു്.
യാഹൂ ZWJ-നെ കളയുന്നില്ല.രണ്ടുതരം ഫലങ്ങളും തരുകയും ചെയ്യുന്നു.
msn ആകട്ടെ ചിലയിടത്തു് അതിനെ കളയുകയും മറ്റിടത്തു് നിലനിര്ത്തുകയും ചെയ്യുന്നു.രണ്ടിലും റെന്ഡറിങ് വീഴ്ചകള് നിലനില്ക്കുന്നതുകൊണ്ടു് ചില്ലുകള് രൂപപ്പെടുന്നില്ല എന്നുമാത്രം.
ശത്രു പക്ഷത്തോടു് സംസാരിക്കുന്നു എന്ന തോന്നല് ഉള്ളതുകൊണ്ടാവാം ഉമേഷിനു് കുത്തുവാക്കായി തോന്നിയതു്(സ്മൈലി കണ്ടില്ലേ).അങ്ങനെ നോക്കുകയാണെങ്കില് മേല്ക്കമന്റില് രചനയെപ്പറ്റിപ്പറയുമ്പോഴും താങ്കള് കുത്തുവാക്കല്ലെ ഉപയോഗിച്ചതു്?
-സുരേഷ്
സന്തോഷ് തോട്ടിങ്ങല് | 05-Feb-08 at 5:09 pm | Permalink
ഉമേഷ്ജീ,
ഞാനുപയോഗിക്കുന്നതു് ഡെബിയന് ലെന്നിയില് ഐസ്വീസല് ആണു്. റിസള്ട്ട് പേജില് റെന്ഡറിങ്ങ് ശരിയാവുന്നില്ല എന്നൊരു പ്രശ്നം മാത്രമേ യാഹൂ സെര്ച്ചിനു് കണ്ടുള്ളൂ. ഉമേഷ് ഉപയോഗിയ്ക്കുന്ന Internet Exploiter ല് റെന്ഡരിങ്ങ് പ്രശ്നമാണോന്നു് നോക്കാന് ആ സെര്ച്ച് റിസള്ട്ട് ഒരു ടെക്സ്റ്റ് എഡിറ്ററിലേയ്ക്കു പേസ്റ്റി നോക്കൂ.
ഇനി പറയൂ, ആര്ക്കാ പ്രശ്നം? 🙂
ജീമെയിലില് ബഗ്ഗുണ്ടായിരുന്നെന്നും അതു് ഇപ്പോള് തിരുത്തിയെന്നതും എല്ലാവരും അറിഞ്ഞുകാണുമല്ലോ…
സന്തോഷ് | 05-Feb-08 at 5:34 pm | Permalink
ഭാഷാസ്നേഹികളും കമ്പ്യൂട്ടിംഗ് വിദഗ്ദ്ധരും വിഷയത്തെപ്പറ്റി പഠിച്ചിട്ട് അഭിപ്രായം പറയേണ്ടുന്ന സമയമായി എന്ന് ഇന്ഡിക് ലിസ്റ്റ് വായിക്കുമ്പോള് പലപ്പോഴും തോന്നാറുണ്ട്. ഈ ലേഖനം ആ ലക്ഷ്യം കൈവരിക്കാന് സഹായിക്കുമെന്ന് വിശ്വസിക്കുന്നു.
(മാന്യ മഹാജനങ്ങളേ, MSN സേര്ച്ച് എന്നൊരു സാധനമില്ല!!
നിങ്ങള് ഉദ്ദേശിക്കുന്ന സാധനത്തിനെ ലൈവ് സേര്ച്ച് എന്നു തന്നെ പറയണം. അറിയാമെങ്കിലും തെറ്റു പറയുന്നവര്ക്ക് മാപ്പില്ല. 🙂 )
ഇഞ്ചിപ്പെണ്ണ് | 05-Feb-08 at 7:20 pm | Permalink
അവസാനം ഈ ചില്ല് പ്രശ്നം എന്തെങ്കിലുമൊക്കെ മനസ്സിലായിത്തുടങ്ങി.
എന്തായാലും എന്നെപ്പോലെ അധികം ടെക്നിക്കല് വിവരമില്ലാത്ത സാധാരണ ആളുകള്ക്ക് എന്റെ ഐഇയില് ഗൂഗിള് സേര്ച്ചില് അവന് എന്ന് സേര്ച്ചിയാല് അവന് എന്ന് കിട്ടോ അതോ അവന് എന്ന് കിട്ടോ? ഇത് എപ്പൊ അവന് എന്ന് കിട്ടുമെന്ന് മാത്രം അറിഞ്ഞാല് മതി എനിക്ക്. അല്ലെങ്കില് എന്താ അതിതുവരേയും അവന് എന്ന് വെച്ചുകൊണ്ടിരിക്കുന്നതെന്നും.
* ഞാന് ഐയിയാണ് ഉപയോഗിക്കുന്നതു. ഗൂഗിള് സേര്ച്ചും.
(ഇതാണ് ഞങ്ങള് നേരത്തേ അവള് എന്ന് പേരിട്ടത്, ഞങ്ങള്ക്ക് ഈ വക ആറ്റോമിക്ക് പ്രശ്നങ്ങളില്ല.)
ഇഞ്ചിപ്പെണ്ണ് | 05-Feb-08 at 7:22 pm | Permalink
ഓഹോ! ഇപ്പൊ ചെയ്തു നോക്കി. അവള് എന്നതിനു അവള് എന്നാണല്ലേ കിട്ടാ? അതു ശരി. എല്ലാത്തിനും അപ്പൊ അതാണല്ലേ കിട്ടാ?
സെബിന് | 05-Feb-08 at 8:28 pm | Permalink
‘ചില്ലു മേടയിലിരുന്നെന്നേ…’ എന്നു പാടിയതു് ഈ ചില്ലിനെ പറ്റിയാണോ? 🙂
സിബു | 05-Feb-08 at 8:34 pm | Permalink
ഗൂഗിളും യാഹൂവും മറ്റും ZWJ-നെ എന്തു ചെയ്യുന്നു എന്നത് ഒന്നിന്റേയും വാദമുഖമല്ല. ഞാന് നേരത്തേ പറഞ്ഞപോലെ, യുണീക്കോഡ് തന്നെ ഇല്ലാതെ, എല്ലാം ഫോണ്ട് എന്കോഡിംഗ് ആയിരുന്നാല് പോലും കമ്പനികള് എന്തെങ്കിലും സെന്സിബിള് ആയിട്ടുള്ളത് ചെയ്തേനേ.
A എന്ന ഒരു റെപ്രസെന്റേഷനില് നിന്നും B എന്നൊരു റിപ്രസന്റേഷനിലേയ്ക്ക് മാറ്റുമ്പോള് B യുടെ ആവശ്യത്തിനുപകരിക്കാത്തതൊക്കെ B എടുത്തുകളയും എന്നത് സ്വാഭാവികമാണ്. ഒരു 3ഡി ചിത്രത്തിനെ പേപ്പറില് വരയ്ക്കുമ്പോള് അതിലെ ഡെപ്ത് പോയ്പ്പോകുന്ന പോലെ.
ഇപ്പറഞ്ഞതിനുസമാനമായ പ്രോഗ്രാമുകളിലെ ഒരു ഉദാഹരണം നോക്കുക. ഒരു വെബ് പേജില് ഒരു വാക്ക് ബോള്ഡാക്കി കാണിക്കാന് ഉപയോഗിക്കുന്ന ബോള്ഡ് ഫോര്മാറ്റിംഗ് കോഡ് 333 ആണെന്നുവയ്ക്കുക. അങ്ങനെ ബോള്ഡ് ഫോര്മാറ്റിംഗ് കോഡ് ഇട്ട് ബോള്ഡാക്കിയ ഒരു വാക്കിനെ ഒരു നോട്ട് പാഡിലേയ്ക്ക് കോപ്പിചെയ്യുന്നു എന്നും വയ്ക്കുക. നോട്ട് പാഡ് എന്ന പ്രോഗ്രാമില് വാക്കുകളെ ബോള്ഡാക്കിക്കാണിക്കാനുള്ള ഉപാധി ഇല്ലാത്തതിനാല് അത് 333 എന്നുകണ്ടാല് അതിനെയൊക്കെ പെറുക്കിക്കളയും. തിരിച്ച് നോട്ട്പാഡില് നിന്നും ബ്രൌസറിലേയ്ക്ക് കോപ്പിചെയ്താല് ആ വാക്കുകളൊന്നും ബോള്ഡായിരിക്കുകയില്ല. നോട്ട് പാഡിന് ബോള്ഡ് എന്താണെന്നറിയില്ല; ഒരു യൂസര് പ്രതീക്ഷിക്കുന്ന രീതിയും ഇതുതന്നെയാണ്. ഇതില് ഒരു പൊരുത്തക്കേടുമില്ല.
ഇനി മലയാളം യുണീക്കോഡ് സ്റ്റാന്റേഡ് ഇങ്ങനെ ഒരു ക്ലോസ് കൊണ്ടുവരുന്നു എന്ന് വയ്ക്കുക: ഒരു മലയാളം അക്ഷരത്തെ കൂട്ടക്ഷരമാക്കാന് അക്ഷരങ്ങള്ക്കിടയില് 333 ഇട്ടാല് മതി എന്ന്. ഇപ്പോള് എന്തുസംഭവിക്കും? മലയാളം വാചകങ്ങള് നോട്ട്പാഡിലേയ്ക്ക് കോപ്പിചെയ്താല് കൂട്ടക്ഷരങ്ങള് മുഴുവന് തെറ്റായിപ്പോകും. എന്തുകൊണ്ടാണ് മലയാളത്തില് മാത്രം ഇങ്ങനെ സംഭവിച്ചത്? 333 എന്ന കോഡിന്റെ സ്വാഭാവികമായ അര്ത്ഥത്തില് നിന്നും വ്യതിചലിച്ച് പ്രതേകമായൊരു അര്ഥം അതിന് മലയാളത്തിന്റെ കാര്യത്തില് മാത്രം കൊടുത്തതുകൊണ്ടാണ്. അപ്പോള് നോട്ട്പാഡ് എഴുതിയിരിക്കുന്ന പ്രോഗ്രാമില്, കോപ്പിചെയ്തത് മലയാളമാണെങ്കില് മാത്രം, 333 എടുത്തുകളയരുത് എന്ന് പ്രത്യേകം എഴുതിച്ചേര്ക്കേണ്ടിവരും. ഇത് എളുപ്പമോ ബുദ്ധിമുട്ടോ ആവുന്നത് ആ പ്രോഗ്രാം എങ്ങനെ ഡിസൈന് ചെയ്തിരിക്കുന്നു എന്നതിനെ ആശ്രയിച്ചിരിക്കും. ലോകത്തിലെ പല ലിപികളുടേയും കമ്പ്യൂട്ടറിലെ ഉപയോഗം വച്ചു നോക്കുമ്പോള് മലയാളം സപ്പോര്ട്ടിനുള്ള പ്രയോരിറ്റി ഇന്നും വളരെ കുറവാണ്. അതുകൊണ്ട് അധികം റിസോര്സസില്ലാത്ത ഡെവലപ്പര്മാരും കമ്പനികളും വിചാരിക്കും ‘ഓ.. ഈ മലയാളം ഭാഷയിലൊക്കെ ആരെഴുതാനാ? അതില്ലാത്ത സപ്പോര്ട്ട് ഒക്കെ മതി’. ഒരു ഉദാഹരണം ഇതാ. തീര്ച്ചയായും ആ അപ്ലിക്കേഷന് കുറെ യൂസര്മാരെ നഷ്ടപ്പെടും. എന്നാല് എന്നെ സംബന്ധിച്ചിടത്തോളം പ്രശ്നം, പല പ്രോഗ്രാമുകളിലും മലയാളം സപ്പോര്ട്ട് ശരിയല്ലാതാവുന്നതാണ്. മലയാളത്തിനുവേണ്ടി പ്രത്യേകം കോഡെഴുതാതെ തന്നെ യുണീക്കോഡില് എഴുതിയ മലയാളം കാണിക്കുകയോ വിനിമയം ചെയ്യുകയോ വേണം എന്നതാണ് എന്റെ ആഗ്രഹം.
മുകളില് പറഞ്ഞ ഉദാഹരണത്തിന്ന് വളരെ സമാനമാണ് ഇന്നത്തെ ചില്ലുകളുടെ സ്ഥിതി. അറ്റോമിക് ചില്ലുവരുമ്പോള് ഇങ്ങനെ ഒരു ഫോര്മാറ്റിം കോഡ് ഉപയോഗിച്ച് ചില്ലുകളെ അവതരിപ്പിക്കേണ്ട അവസ്ഥയില്ല; മലയാളത്തിന് വേണ്ടി പ്രത്യേകം അപ്ലിക്കേഷനുകള് മാറ്റേണ്ടതില്ല. അതുകൊണ്ടാണ് അറ്റോമിക് ചില്ലുകള് മലയാളത്തിന് ഗുണകരമാവുന്നത്.
Ralminov | 06-Feb-08 at 12:14 am | Permalink
‘ഉദാഹരണമായി മലയാളത്തിലെ ഓരോ കോഡിനും മൂന്നു ബൈറ്റു് ഉപയോഗിക്കുന്ന utf-8 എന്ന രീതിയില്”
മുകളില് പറഞ്ഞിരിക്കുന്നതില് ഒരു തിരുത്തു് വേണമല്ലോ. UTF-8 സിങ്കിള് ബൈറ്റ് ആണു്, പേരു് സൂചിപ്പിക്കുന്നതു് പോലെ. അതിലെ ഏഴ് ബിറ്റുകള് അക്ഷരങ്ങളെയും ഒന്നു് ഭാഷയെയും കുറിക്കാനുപയോഗിക്കുന്നുവെന്നാണു് ഞാന് മനസ്സിലാക്കിവെച്ചിരിക്കുന്നതു്.
എ.ആര് റഹ്മാന് എന്നല്ല എ.ആര് റഹ്മാന് എന്നാണു് എപ്പോഴും കാണിക്കേണ്ടതു്. ഗൂഗ്ള് ഒരിക്കലും അതു് കാണിക്കില്ല, രചന ഫോണ്ട് ഉപയോഗിക്കുന്നവരെ.
മരം വെട്ടറിയാത്തതിനു് കോടാലിക്കു് തെറിയും.
Ralminov | 06-Feb-08 at 12:35 am | Permalink
UTF-8 നെപറ്റിയുള്ള എന്റെ പരാമര്ശത്തിലും പിശകുണ്ടെന്നു് തോന്നുന്നു.
Anyway, it must be a single byte scheme.
Ralminov | 06-Feb-08 at 12:41 am | Permalink
എന്റെ പരാമര്ശത്തിലാണു് പിശകു്. I stand corrected.
മലയാളം UTF8 മൂന്നു് ബൈറ്റ് തന്നെയാണു്.
Umesh:ഉമേഷ് | 06-Feb-08 at 12:47 am | Permalink
കോടാലിയ്ക്കും മരത്തിനും എത്ര ബിറ്റുകള് വേണമെന്നറിയില്ല, പക്ഷേ utf-8-ല് ഒരു ബിറ്റു ഭാഷയ്ക്കും ഏഴു ബിറ്റു് അക്ഷരങ്ങളെയും കാണിക്കുന്നു എന്നു റാല്മിനോവ് പറഞ്ഞതു തെറ്റാണു്.
utf-8-ല് സിംഗിള് ബൈറ്റുകളുടെ ശ്രേണിയായാണു ടെക്റ്റ് സൂക്ഷിക്കുന്നതു്. പക്ഷേ അതില് ഒരു യൂണിക്കോഡ് കോഡ് (അക്ഷരം എന്നു പറയാം) സൂക്ഷിക്കുന്നതു ഒന്നോ രണ്ടോ മൂന്നോ നാലോ ബൈറ്റിലാണു്.
മലയാളത്തിനു യൂണിക്കോഡില് മൂന്നു ബൈറ്റുകള് ആവശ്യമാണു്. മലയാളം മാത്രമല്ല, മറ്റു കുറേ ഭാഷകള്ക്കും. ഈ 24 ബിറ്റുകളില് 8 ബിറ്റുകള് അതൊരു മൂന്നു ബൈറ്റിന്റ്റെ ശ്രേണിയാണു് എന്നു സൂചിപ്പിക്കുന്നു. ബാക്കി 16 ബിറ്റുകളിലാണു് അക്ഷരങ്ങളുടെ സംഖ്യകള് സൂക്ഷിക്കുന്നതു്.
കൂടുതല് വിവരങ്ങള്ക്കു് വിക്കിപീഡിയ ലേഖനം നോക്കുക.
ഭാഷ സൂചിപ്പിക്കാന് ഒരു ബിറ്റു മതിയെങ്കില് ആകെ രണ്ടു ഭാഷയേ ഉള്ളോ റാല്മിനോവേ യൂണിക്കോഡില്? ഒരു ബിറ്റു കൊണ്ടു രണ്ടു വ്യത്യസ്ത കാര്യങ്ങള് മാത്രമേ സൂചിപ്പിക്കാന് പറ്റൂ എന്നാണു് എന്റെ അറിവു്.
Umesh:ഉമേഷ് | 06-Feb-08 at 12:50 am | Permalink
റാല്മിനോവിന്റെ ആദ്യത്തെ കമന്റ് മാത്രമേ മറുപടി എഴുതുമ്പോള് കണ്ടിരുന്നുള്ളൂ. ഞാന് എഴുതിയപ്പോഴേയ്ക്കു റാല്മിനോവ് രണ്ടു കമന്റുകള് കൂടിയിട്ടു.
അപ്പോള് utf8-ന്റെ കാര്യത്തില് ഒരു തീരുമാനമായി. അല്ലേ? 🙂
suresh | 06-Feb-08 at 2:13 am | Permalink
തിരിഞ്ഞുതിരിഞ്ഞു് സിബു വീണ്ടും ഫോര്മാറ്റു് കണ്ട്രോള് വാദത്തില് ചെന്നെത്തി.അതുകൊണ്ടു് മുന്പു പറഞ്ഞതുതന്നെ ആവര്ത്തിക്കുന്നു.ജോയ്നറുകളെ bold/italic ഫോര്മാറ്റുകളുമായി താരതമ്യം ചെയ്യാനൊക്കില്ല(എങ്ങനെ നിര്വചിച്ചിരിക്കുന്നു എന്നതല്ല,എങ്ങനെ പ്രവര്ത്തിക്കുന്നു എന്നതിനെ ആധാരമാക്കി വേണം കളയണോ വേണ്ടയോ എന്നു് തീരുമാനിക്കാന്).വേണമെങ്കില് -നോടു് താരതമ്യം ആവാം.ശൂന്യതയല്ലെ എന്നു കരുതി എല്ലാ -ഉം എടുത്തുകളഞ്ഞാല് എന്താകും സ്ഥിതി! (ചില ഭാഷകള്ക്കു് സ്പേസ് ആവശ്യമായി വരുന്നില്ല.അവ പ്രശ്നമൊന്നും കാണിക്കുകയുമില്ല).പരിചരണവേളയില് അപ്ലിക്കേഷനുകള്ക്കു് അധികപ്പടിയായവ ഉപേക്ഷിക്കാം എന്നുമാത്രം.
അപ്പോള് പ്രധാനകാര്യം ഇതുതന്നെ:
“അതുകൊണ്ട് അധികം റിസോര്സസില്ലാത്ത ഡെവലപ്പര്മാരും കമ്പനികളും വിചാരിക്കും ‘ഓ.. ഈ മലയാളം ഭാഷയിലൊക്കെ ആരെഴുതാനാ? അതില്ലാത്ത സപ്പോര്ട്ട് ഒക്കെ മതി’.”
അതായതു് ‘വെണ്ടര്മാര് വാഴ്ക’ എന്നു്.
വെണ്ടറോ ഭാഷയോ പ്രധാനം എന്നു് വായിക്കുന്നവര് തീരുമാനിക്കുക.ടൈപ്റൈറ്ററിനുവേണ്ടി ലിപിയെ മുറിച്ചു.ഇന്നു ടൈപ്റൈറ്റര് ആവശ്യമില്ല.മുറിച്ചെഴുതിയതെല്ലാം അങ്ങനെത്തന്നെ കിടക്കുന്നു.ചരിത്രപരമായ മണ്ടത്തരങ്ങളും ആവര്ത്തിക്കേണ്ടതാണെന്നോ?
-സുരേഷ്
suresh | 06-Feb-08 at 2:22 am | Permalink
മേല്ക്കമന്റില് തിരുത്തു്:
… വേണമെങ്കില് Space-നോടു് താരതമ്യം ആവാം.ശൂന്യതയല്ലെ എന്നു കരുതി എല്ലാ Space-ഉം …
Verbatim തരാവില്ല അല്ലേ:( കമന്റ് പ്രിവ്യുവിനു് ഏതെങ്കിലും wordpress plugin ഉപയോഗിച്ചാല് തരക്കേടില്ലായിരുന്നു.
-സുരേഷ്
സിബു | 06-Feb-08 at 2:39 am | Permalink
സുരേഷ്, തീര്ച്ചയായും വിയോജിപ്പുണ്ട്. കേരളത്തിലെ കോടതിയില് വിധിപ്രസ്താവിക്കേണ്ടത് ഭരണഘടന നോക്കിയല്ല; ബീഹാറിലും തമിഴ്നാട്ടിലേയും നാട്ടുനടപ്പ് എങ്ങനെയാണ് എന്നു നോക്കിയാണ് എന്നുപറയും പോലെ അസംബന്ധമാണിത്.
സ്റ്റാന്റേഡുകളിലെ നിര്വചനങ്ങള് തന്നെയാണ് ഏതൊരു ഇമ്പ്ലിമെന്റേഷന്റേയും ആധാരം. ഉദാഹരണത്തിന് ആരും ഗൂഗിള് എങ്ങനെയാണ് HTML ഇമ്പ്ലിമെന്റ് ചെയ്തിരിക്കുന്നത് എന്നുനോക്കിയല്ല സ്വന്തം HTML പ്രോട്ടോക്കോള് ഇമ്പ്ലിമെന്റ് ചെയ്യുന്നത് – അങ്ങനെ ചെയ്യാന് പാടില്ല താനും. ഇനി സ്റ്റാന്റേഡിന്റെ നിര്വ്വചനങ്ങളില് പ്രശ്നങ്ങളുണ്ടെങ്കില് അത് സ്റ്റാന്റേഡിനെ തിരുത്തിത്തന്നെയാണ് തീര്ക്കേണ്ടത്.
ZWJ എന്നത് ഒരു ഭാഷാപരമായി ഒരേ അര്ഥമുള്ള രണ്ടു രൂപങ്ങളെ വേര്തിരിച്ചു കാണിക്കാനുപയോഗിക്കുന്ന ഫോര്മാറ്റിംഗ് ചിഹ്നമാണ് എന്നത് ആവര്ത്തിക്കട്ടേ. ഉമേഷ് ഇത് ഗ്ദ്ധ കൂട്ടക്ഷരത്തിന്റെ ഉദാഹരണംകൊണ്ട് വിശദമാക്കിയിട്ടുണ്ട്. അതുകൊണ്ട് തന്നെ, അതിനെ ‘-‘ ആയി താരതമ്യം ചെയ്യുന്നതും ശരിയല്ല.
suresh | 06-Feb-08 at 3:47 am | Permalink
സിബൂ,
നേരത്തെ കമന്റ് തൊടുത്തുവിട്ടപ്പോള് പറ്റിയ തെറ്റ് തിരുത്തിയതു് കണ്ടുകാണുമല്ലോ.
അതെ, ഭരണഘടന അനുസരിക്കേണം.എന്നാല് മറ്റൊരു വശമുണ്ടു്.ഭരണഘടന വേദപുസ്തകങ്ങള് പോലെയല്ല.അബദ്ധങ്ങള് ഒഴിവാക്കാനും കാലികപ്രസക്തിക്കും വേണ്ടി അവ കാലാനുസൃതമായി തിരുത്താറുണ്ടു്.
വിചിത്രമായ ഭരണഘടന പലരാജ്യങ്ങളിലും നിലനിന്നിരുന്നു/നിലനില്ക്കുന്നു.അവ നിരാകരിക്കേണ്ടതായി വരും.പിന്നീടു് ഭരണത്തിനു് വിവേകം വരുമ്പോള് അവ പലതും തിരുത്തിനു് വിധേയമാവുകയും ചെയ്യും.ഇന്നുള്ള മനുഷ്യാവകാശങ്ങള് പലതും അങ്ങനെ കൈവന്നവയാണു്.
ഒരു സാങ്കല്പിക ചിത്രം:
തലതിരിഞ്ഞ സൌന്ദര്യസങ്കല്പം മൂലം ഒരു ഭരണാധികാരി ഭരണഘടയില് ചേര്ക്കുന്നു, അംഗവൈകല്യമുള്ള എല്ലാ വ്യക്തികളേയും നിര്മാജ്ജനം ചെയ്യണമെന്നു്.അതു പ്രകാരം എല്ലാവരും പ്രവര്ത്തിച്ചാല് എന്താകും സ്ഥിതി? പിന്നിടു് വരുന്ന ഒരു പരിണതപ്രജ്ഞനു് നഷ്ടപ്പെട്ടവരെയെല്ലാം തിരിച്ചുകൊണ്ടവരാന് കഴിയുമോ?
-സുരേഷ്
പ്രവീണ് | 06-Feb-08 at 4:32 am | Permalink
ഉമേഷ്ജി എന്റെ ചോദ്യത്തിനുത്തരം തന്നില്ല. ഈ കൊളേഷന് എന്നു് പറയുന്ന സാധനം എന്താണെന്നൊന്നു് വിശദീകരിയ്ക്കാമോ?
സിബു | 06-Feb-08 at 4:34 am | Permalink
തീര്ച്ചയായും ഇപ്പോഴത്തെ യുണീക്കോഡില് ചില്ലുകള് പ്രശ്നക്കാരാണ്. അത് നേരെയാക്കുകയാണല്ലോ അടുത്ത വെര്ഷനില് സംഭവിക്കുന്നത്. ആ രീതിയില് സുരേഷ് പറഞ്ഞപോലെ തന്നെ, വളരെ മുമ്പേ നടക്കേണ്ടിയിരുന്ന ഒരു തിരുത്തലാണ് ഇപ്പോള് നടക്കുന്നത്.
കോവാല കൃഷ്ണന് | 06-Feb-08 at 4:44 am | Permalink
വന്നല്ലോ പ്രാവീണ്യമുള്ളവന്, പ്രവീണന്. കൊളേഷന് അറിയാത്ത പ്രവീണാണോ “പൂച്ചക്ക് പാലു കൊടുക്കുന്നത്”? ഒരു കാര്യം ചെയ്യ്. കൊളേഷന് എന്താണെന്ന് പ്രവീണിനറിയാവുന്ന കാര്യം ഇങ്ങോട്ട് പറ. ബാക്കി പറയാന് ഞാനും കൂടാം. റാല്മിനോവന് UTF-8 പറഞ്ഞതു പോലെ ആവല്ലേ.
പ്രവീണ് | 06-Feb-08 at 4:56 am | Permalink
വെബ്ദുനിയയിലെ ഫലം
പ്രവീണ് | 06-Feb-08 at 5:23 am | Permalink
റാല്മിനോവന് പറഞ്ഞതിനെന്താ കുഴപ്പം? തെറ്റു് മനസ്സിലാക്കി തിരുത്തിയതോ? തെറ്റാണെന്നറിഞ്ഞാലും കെട്ടിപ്പിടിച്ചിരിയ്ക്കണമെന്നാണോ കോവാലന് പറയുന്നതു്?
പ്രവീണ് | 06-Feb-08 at 5:50 am | Permalink
ഉമേഷ്ജി രണ്ടു് ചോദ്യമായിപ്പോ ഉത്തരം കിട്ടാതെ കിടക്കുന്നു. ഇനിയുെ ചോദിയ്ക്കാനുണ്ടേയ് 🙂
അത്രയും ലേഖനങ്ങളാക്കിയിട്ടും ആര്ക്കും മനസ്സിലായില്ലെന്നു് തോന്നുന്നു. അതുകൊണ്ടിനി ഇങ്ങനെ ചെറിയ ചെറിയ ചോദ്യങ്ങളാവാം.
Umesh:ഉമേഷ് | 06-Feb-08 at 5:58 am | Permalink
സന്തോഷ്,
ആരുടെയോ ബ്ലോഗില് ഇന്നു കണ്ടു. ഉറപ്പാക്കാതെ എഴുതിയതില് ക്ഷമിക്കുക. ഇപ്പോള് ഓര്മ്മ വന്നു. അനിവറിന്റെ പൈറസി പോസ്റ്റില്.
ടെക്നിക്കല് കാര്യങ്ങള് മനഃപൂര്വ്വം മിണ്ടാതിരുന്നതാണു്. സിബുവും സുറുമയുമൊക്കെ ഡിസ്കസ് ചെയ്തു തീരട്ടേ. എനിക്കും കുറച്ചു പഠിക്കാനുണ്ടു് അവയില് നിന്നു്. ഇതെല്ലാം ഞാന് വേറൊരു പോസ്റ്റായി എടുത്തു വെയ്ക്കുന്നുണ്ടു്. ഒന്നിച്ചു് അഭിപ്രായം പറയാം.
യാഹൂ ZWJ എടുത്തു കളയുന്നില്ല എന്നു സന്തോഷ് പറഞ്ഞതു ശരിയാണു് എന്നു ഞാന് വേരിഫൈ ചെയ്തു. എന്തുകൊണ്ടു് ചില്ലു കാണുന്നില്ല എന്നതു നോക്കിക്കൊണ്ടിരിക്കുകയാണു്.
പിന്നെ, കൊളേഷന്. മലയാളം കൊളേഷനെപ്പറ്റിത്തന്നെ ഒരു പോസ്റ്റ് അല്പം മുമ്പു് എഴുതിത്തുടങ്ങിയതു പൂര്ത്തിയാകാതെ കിടക്കുന്നു. ശബ്ദതാരാവലി മുതല് പല സ്ഥലങ്ങളിലും അകാരാദിക്രമം വ്യത്യസ്തമാണു്. കേരളസര്ക്കാരിന്റെ ഒരു ഡോക്യുമെന്റും കണ്ടു. ഇവയില് ഏതാണു് അഭികാമ്യം എന്നതിനെപ്പറ്റി. യൂണിക്കോഡില് ഇപ്പോള് ഉള്ളതു പര്യാപ്തമല്ല താനും. അതില് അറ്റോമിക് ചില്ലിനനുകൂലമായും എതിരായും ഉള്ള പ്രശ്നങ്ങളും ചേര്ക്കാം.
അങ്കിള് | 06-Feb-08 at 6:14 am | Permalink
ഇനിയുണ്ടാകുന്ന കമന്റുകള് അറിയാന് വേണ്ടിയാണേ.
എന്നാലും ഒന്നറിയാന് മോഹം. ഈ പോസ്റ്റെഴുതാന് ഉമേഷ് എത്ര മണിക്കൂര് എടുത്തിരിക്കും? വേറെ ചില കാര്യങ്ങള്ക്കുത്തരം കിട്ടാനാണേ….
viswam | 06-Feb-08 at 6:14 am | Permalink
Dear Anivar,
I just happened to see and read a link from this post to your blog. It seems you have somehow had the impression that the “Kovalan” is myself. Let me categorically state that it is not me. I had not seen that post/discussion (like many of the Malayalam blogs now-a-days,)until this moment.
I do not appear as anonymous or impersonated IDs anywhere in the blogs/forums. If at all I must (due to log-in issues, I always try to add my name underneath the comment as part of it.
സുനില് | 06-Feb-08 at 7:26 am | Permalink
ഇനി ഇതുവായിച്ച് കണ്ഫ്യൂഷന് തീര്ക്കാം!!!
suresh | 06-Feb-08 at 8:34 am | Permalink
സിബു പറയുന്നു ഇപ്പോഴത്തെ യുണിക്കോഡില് ചില്ലുകള് പ്രശ്നക്കാരാണെന്നു്.
യഥാര്ത്ഥത്തില് എന്തുപ്രശ്നമാണു് ഒരു സാധാരണ യൂണിക്കോഡ് മലയാളം യൂസര്ക്കു് അനുഭവപ്പെടുന്നതു് എന്നു നോക്കൂ.അതു റാല്മിനോവു് പറഞ്ഞതുപോലുള്ള പ്രശ്നങ്ങളാണു്.അതിനു പരിഹാരം ആണവചില്ലല്ല.
ആ ‘റഹ്മാന്’ ഉദാഹരണം വളരെ പ്രസക്തമാണു്.’റഹ്മാന്’ എന്നെഴുതിയാല് വായിക്കുന്നതും അങ്ങനെയാണു്.എന്നാല് ‘റഹ്മാന്’ എന്നതില് അങ്ങനെയല്ല.’ഹ്മ’ എന്ന കൂട്ടക്ഷരം ഉച്ചാരണത്തില് ‘മ്ഹ’ എന്നായി മാറും.(ഉദാ: ബ്രഹ്മം.യേശുദാസിന്റെയോ ജയചന്ദ്രന്റെയോ ചില സിനിമാഗാനങ്ങള് ഒന്നു് ഓര്ത്തുനോക്കൂ.ഉച്ചാരണത്തില് ഇരുവരും സ്വതേ കണിശക്കാരാണു് ). ‘ഹ്ന’ കാര്യത്തിലും ഇതു തന്നെയാണു് കഥ.ഭാഷയില് നിലനില്ക്കുന്ന ചില rare exceptions ആണിവ.
-സുരേഷ്
കൃഷ് | krish | 06-Feb-08 at 10:00 am | Permalink
ആറ്റോമിക്ക് ചില്ലുകള് എന്ന കുന്തം വിഴുങ്ങിയിരുന്നതാ.. ഇപ്പം ഏതാണ്ടൊക്കെ കുറച്ച് മനസ്സിലായിന്ന് തോന്നണ്. എന്തോ?
ഐ.ഇ.7 നും ഫയര്ഫോക്സ് 2 ഉം ഉപയോഗിക്കുന്നുണ്ട്. ഐ.ഇ.7 ഇടക്കിടക്ക് തന്നെത്താന് ഹാങ്ങ് ആവുകയോ/ക്ലോസ് ആവുകയോ ചെയ്യുന്നു. ഫയര്ഫോക്സില് മലയാളം ചില്ല് /കൂട്ടക്ഷരങ്ങള് വേറിട്ടാണ് കാണിക്കുന്നത്. അതുകൊണ്ട് മലയാളം അതില് വായിക്കാന് വലിയ ബുദ്ധിമുട്ടാണ്. ഇത് എങ്ങനെ ശരിയാക്കാം. ഫയര്ഫോക്സ് 3 ഇറങ്ങിയാല് ഈ പ്രശ്ശം പരിഹരിക്കുമെന്ന് കേള്ക്കുന്നു. ഫയര്ഫോക്സ് 3 ബീറ്റ വെര്ഷനല്ലെ ഇപ്പോള് ഇറങ്ങിയിട്ടുള്ളൂ. ഫൈനല് വെര്ഷന് എപ്പോള് ഇറങ്ങും.
(പിന്നെ കീമാനില് ടൈപ്പ് ചെയ്യുമ്പോള് ‘അടിവര’ ഉപയോഗിച്ച് ചില വാക്കുകള് നേരെ ടൈപ്പ് ചെയ്യാമല്ലോ . ഉദാ: പിന്_വലി = പിന്വലി /അല്ലെങ്കില് ഇങ്ങനെ കാണിക്കും: പിന്വലി)
Moorthy | 06-Feb-08 at 10:30 am | Permalink
ഉമേഷ്ജി ഓഫിനു മാപ്പ്.
പ്രിയ കൃഷ്,
ഈ സെറ്റിങ്ങ്സ് ഒന്നു പരിശോധിക്കുമോ?
Tools->Options->Content->default font=anjalioldlipi ആക്കുക. എന്നിട്ട് അതിലെ Advanced എടുക്കുക. താഴെ പറയുന്ന രീതിയില് സെറ്റ് ചെയ്യുക.
fonts for = malayalam
proportional = sans serif
serif= anjalioldlipi
sans serif= anjalioldlipi
mono space = anjalioldlipi
allow pages to choose their own fonts….. എന്നതില് ടിക്ക് ഉണ്ടെങ്കില് മാറ്റുക.
default character encoding = Unicode(UTF8)
എന്റെ മൊസില്ല ഫയര്ഫോക്സില് ഇത്രയും ചെയ്തപ്പോള് ചില്ല് ശരിയായി. ചില ബ്ലോഗുകളിലെ ടൈപ്പിങ്ങ് തകരാര് മൂലമുള്ള ചില്ല് പ്രശ്നം മാത്രമെ ഇപ്പോള് ഉള്ളൂ..
ഇതാണോ ഏറ്റവും നല്ല വഴി എന്നറിയില്ല..
P.C.Madhuraj | 06-Feb-08 at 1:00 pm | Permalink
Do we foret that language starts with pronounciation and not with script?(It can have many scripts but only one pronounciation- one “aksharaSabdavyavastha padaaRthavyavastha” It is quite possible that a script of malayalam is incompetent to write the name “Rahman”, word of a different language. Those who know the word can pronounce it in “the right” way. When we write the word “bank” in malayalam, it is either “baank” or “bEnk”. But we pronounce it the “English way” with a swara that is neither ‘aa’ nor ‘E’.
I write “aafrikka” and “phalam” in malayalalam; knowing the words, we pronounce the english syllable “fa” and malayalam syllable “pha” differently (and correctly).
The problem that Umesh faced while tracking “avan” is an extension of an older problem created by poets- they started using “sambandhika” without “dvithvam”- and in sandhi with a word starting on a vowel, it became impossible to distinguish “sambandhika”(avannu, rAmannu) separately from “vyavaharika”(rAman, avan).
Confusion is also because of this- not entirely due to it- I guess.
സിബു | 06-Feb-08 at 4:12 pm | Permalink
പൊതുവെ ഉള്ള ഒരു തെറ്റിദ്ധാരണയാണ് ഇത് 70-ലെ ലിപിപരിഷ്ക്കരണം പോലുള്ള എന്തോ ഒന്നാണ് യുണീക്കോഡില് സംഭവിക്കുന്നത് എന്ന്. അല്ലേ അല്ല. ഇതില് മലയാളത്തിന്റെ ലിപി ഇന്നതായിരിക്കണം എന്ന് ഇവിടെ തീരുമാനിക്കപ്പെടുന്നേ ഇല്ല.
എഴുത്തിലും പ്രിന്റിലുമായി അനേകം എഴുത്തുരീതികളുണ്ടാകും. അതില് ഒന്ന് പഴയതും മറ്റൊന്ന് പുതിയതാവും, ഒന്ന് നോവലിലും കഥകളിലും സംഭാഷണം രേഖപ്പെടുത്തുന്നതാവും, മറ്റൊന്ന് ശ്ലോകങ്ങളെഴുതാനുള്ളതാവും. ഒന്ന് പണ്ടത്തെ താളിയോലകളിലുള്ളതാവും ഒന്ന് ഇന്ന് ചാറ്റ് ചെയ്യുമ്പോള് പിള്ളേരെഴുതുന്നതാവും. യുണീക്കോഡിന്റെ ഉദ്ദേശം ഇതിലൊന്നാണ് ശരി എന്ന് തീരുമാനിച്ച് അതിനനുസൃതമായി അക്ഷരങ്ങളുടെ എന്കോഡിംഗ് നടത്തുക എന്നതല്ല; മറിച്ച്, മലയാളത്തിന്റെ എല്ലാ ലേഖനസമ്പ്രദായങ്ങളും യുണീക്കോഡില് സാധ്യമാക്കുക എന്നതാണ്.
അതുകൊണ്ട് തന്നെ, മധുരാജേ, ഭാഷാപരമായ കൃത്യതകള്ക്ക് ഇവിടെ വലിയ സ്ഥാനമില്ല. കാരണം അങ്ങനെ മാത്രമല്ലല്ലോ എല്ലാവരും എഴുതാറ്. ഭാഷ ഏതുരീതിയിലിരിക്കണം എന്ന പൊളിറ്റിക്സ് യുണീക്കോഡിന് പുറത്ത് സംഭവിക്കേണ്ടതാണ്.
സുരേഷേ, രാമായണം മുഴുവന് കേട്ടിട്ട് സീത രാമന്റെ ആരായിട്ടുവരും എന്ന് ചോദിച്ച പോലെയായല്ലോ.. ‘അവന്/അവന്’ എന്ന രീതിയിലുള്ള അനേകം ജോടികള് എന്തുകൊണ്ട് കണ്ടില്ല എന്നു നടിക്കുന്നു. അപ്ലിക്കേഷനുകള് ചില്ലിന്റെ പ്രശ്നത്തെ എങ്ങനെ മറികടക്കുന്നു എന്നതേ അല്ല ഇവിടെ വിഷയം. ഇതൊക്കെയും ഉമേഷും ഞാനുമായി മുകളില് എഴുതിത്തീര്ത്തതാണ്.
ഉമേഷ് | Umesh | 06-Feb-08 at 10:34 pm | Permalink
മധുരാജ് പറഞ്ഞു:
Do we foret that language starts with pronounciation and not with script?(It can have many scripts but only one pronounciation- one “അക്ഷരശബ്ദവ്യവസ്ഥ പദാര്ത്ഥവ്യവസ്ഥ”. It is quite possible that a script of malayalam is incompetent to write the name “Rahman”, word of a different language. Those who know the word can pronounce it in “the right” way. When we write the word “bank” in malayalam, it is either ബാങ്ക് or ബേങ്ക്. But we pronounce it the “English way” with a swara that is neither ആ or ഏ.
I write ആഫ്രിക്ക and ഫലം in malayalalam; knowing the words, we pronounce the english syllable “fa” and malayalam syllable ഫ differently (and correctly).
യോജിക്കുന്നു.
മധുരാജ് തുടര്ന്നു പറയുന്നു:
The problem that Umesh faced while tracking അവന് is an extension of an older problem created by poets- they started using സംബന്ധിക without ദ്വിത്വം- and in sandhi with a word starting on a vowel, it became impossible to distinguish സംബന്ധിക (അവന്നു, രാമന്നു) separately from വ്യവഹാരിക (രാമന്, അവന്).
Confusion is also because of this- not entirely due to it- I guess.
സംസ്കൃതത്തിലെ ഷഷ്ഠിവിഭക്തിയെയാവും മധുരാജ് സംബന്ധിക എന്നു പറഞ്ഞതു്. മലയാളത്തില് അവനു്/അവന്നു് എന്നതു് ഉദ്ദേശികാവിഭക്തിയാണു് – രാമനു് (രാമന്നു്). സംബന്ധിക രാമന്റെ എന്നതാണു്. സംസ്കൃതത്തില് രണ്ടും ഷഷ്ഠിയാണു്-രാമസ്യ.
പക്ഷേ, രാമനു് എന്നതു തെറ്റാണെന്നും രാമന്നു് എന്നതേ ശരിയാവൂ എന്നും പറയാന് പറ്റില്ലല്ലോ. ഭാഷയും മാറിക്കൊണ്ടിരിക്കുകയാണല്ലോ.
പതിന്നാലാം നൂറ്റാണ്ടില് എഴുതിയ “ലീലാതിലകം” എന്ന മലയാള(മണിപ്രവാള)വ്യാകരണ-കാവ്യശാസ്ത്രഗ്രന്ഥത്തില് നിന്നു് (ഡയലോഗാക്കി മിനുക്കിയതു ഞാന്. പുസ്തകത്തില് ഇങ്ങനെയല്ല):
ഭാഷയില് ങ, ട, ണ, ര, ല, ഴ, ള, റ, ന (നനയ്ക്കുക എന്നതിലെ രണ്ടാമത്തെ ന) എന്നു് ഒന്പതക്ഷരങ്ങള് പദാദിയില് വരില്ല.
ങേ, അപ്പോള് രവി?
അതു സംസ്കൃതമാണു്.
ലാക്കു്?
സംസ്കൃതത്തിന്റെ അപഭ്രംശം. ശുദ്ധമായ മലയാളമല്ല.
രണ്ടോ?
രണ്ടു് തെറ്റാണു്. ഇരണ്ടാണു ശരി. ഇരണ്ടിനെ രണ്ടെന്നു പറയുന്നതു തെറ്റാണു്.
ഇതു പതിന്നാലാം നൂറ്റാണ്ടിലെ കാര്യം. ഇപ്പോള് രണ്ടു തെറ്റാണു്, ഇരണ്ടാണു ശരി എന്നു പറഞ്ഞാല് ആരെങ്കിലും സമ്മതിക്കുമോ?
viswam | 06-Feb-08 at 10:49 pm | Permalink
സ്വല്പ്പം വൈകിയാണെങ്കിലും,ഈവക കാര്യങ്ങളെക്കുറിച്ച് ചര്ച്ച ചെയ്യാന് എല്ലാംകൊണ്ടും യോഗ്യരായ ഉമേഷും മധുവും മറ്റും രംഗത്ത് എത്തിച്ചേര്ന്നതുകണ്ട് വളരെ സന്തോഷം തോന്നുന്നു.
Jayarajan | 07-Feb-08 at 1:14 am | Permalink
ആദ്യം ഇവിടെ ഒരു 50. വായന പിന്നീട്. (ഹോ ഒരൊറ്റയടിക്ക് 3 പോസ്റ്റ് അല്ലേ ഇട്ട് കളഞ്ഞത്? ) 🙂
ഉമേഷ് | Umesh | 07-Feb-08 at 2:34 am | Permalink
ഇവിടെ പ്രാസംഗികമായി പരാമര്ശിക്കപ്പെട്ട ബ്രഹ്മം/റഹ്മാന് പ്രശ്നവുമായി ബന്ധപ്പെട്ട ഒരു പോസ്റ്റ് ഞാന് ഇവിടെ ഇട്ടിട്ടുണ്ടു്.
അങ്കിള് | 07-Feb-08 at 3:49 am | Permalink
കുറച്ചുനാളായി മനസ്സില് കൊണ്ടുനടക്കുന്നു. പക്ഷേ ഈ ബ്ലോഗില് വന്ന് ഓഫടിക്കാന് മനസ്സിനൊരു വിഷമം. വേറൊരിടത്ത് ചോദിച്ചിട്ട് കാര്യമില്ലാത്തതു കൊണ്ട് ഇവിടെത്തന്നെ ചോദിക്കുന്നു:
ഈ സംവൃതോകാരത്തിലുള്ള വാക്കുകള് അതായത് ഉകാരവും ചന്ദ്രകലയും ചേര്ത്തുള്ളത് കംപ്യൂട്ടറില് എങ്ങനെയാണ് എഴുതാന് പറ്റുന്നത്?. അഞ്ഞലിയും വരമൊഴിയും കീമാനുമാണ് എന്റെ സഹായികള്. അതുകോണ്ടൊന്നും ഉമേഷ് എഴുതുന്ന പല അക്ഷരങ്ങളും എഴുതാന് പറ്റുന്നില്ല.
ഉമേഷിന്റെ പ്രത്യേക സംവിധാനങ്ങള് എന്തോക്കെയെന്ന് മറ്റുള്ളവര് അറിയുന്നതില് എതിര്പ്പുണ്ടോ?
സിബു | 07-Feb-08 at 5:09 am | Permalink
അങ്കിളേ, വരമൊഴി/കീമാനിലാണെങ്കില് u~ എന്നെഴുതിയാല് സംഗതി ശരിയാവും. അതായത്, ‘അതു് = athu~’
അങ്കിള് | 07-Feb-08 at 6:06 am | Permalink
ഈശ്വരാ, ഇത്രയും നിസ്സാര കാര്യവുമായാണോ ഞാനീ പോസ്റ്റിനെ മലിനപ്പെടുത്തിയത്. നന്ദി സിബു.
അങ്കിള് | 07-Feb-08 at 6:08 am | Permalink
സിബു, കമന്റെഴുതിക്കഴിഞ്ഞാണ് ടെസ്റ്റ് ചെയ്തത്. സിബു പറഞ്ഞരീതിയില് ഉകാരാം കാണുന്നില്ലല്ലോ. ഉമേഷ് എഴുതുന്നതില് ഉകാരവും ചന്ദ്രകല യും ഉണ്ട്. അതായിരുന്നു എന്റെ സംശയവും.
സെബിന് | 07-Feb-08 at 6:19 am | Permalink
ഉമേഷേട്ടാ,
ഈ പോസ്റ്റിന്റെ തുടക്കത്തില് സന്തോഷ് തോട്ടിങ്ങല് ചോദിച്ച ചോദ്യത്തിന്റെ അവസാന ഭാഗമില്ലേ ? അതൊന്നു വിശദീകരിക്കാമോ? അതായതു്, നേരത്തെ എഴുതിവന്നിരുന്നു ചില്ലും പുതിയ ആണവ ചില്ലും ഒന്നു തന്നെയാണോ? കാനോനിക്കല് ഈക്വലന്സ് നല്കിയിട്ടുണ്ടോ ? അതില്ലെങ്കില് ഇപ്പോഴത്തെ ടെക്സ്റ്റ് എങ്ങനെ ഡിസ്പ്ലേ ചെയ്യും? സെര്ച്ചിങ്ങിലും സോര്ട്ടിംഗിലും ഈ പ്രശ്നം എങ്ങനെ പരിഹരിക്കും ?
Jayarajan | 07-Feb-08 at 6:36 am | Permalink
പോസ്റ്റും കമന്റും ഒക്കെ വായിച്ചു. അരവിന്ദ്ജീയുടെ കമന്റിന് എന്റെ വകയും ഒരൊപ്പ് ഇടാം എന്ന് വിചാരിച്ചിരിക്കുകയായിരുന്നു (ഏ? എത്രാമത്തെ കമന്റ് എന്നോ? 2 കമന്റിനും. ഹല്ല, പിന്നെ! 🙂 ); പക്ഷേ, ഇവിടെ വോട്ടും പെറ്റീഷനും ശക്തിപ്രകടനവും ഒന്നുമില്ലെന്ന് ഉമേഷ്ജി പറഞ്ഞ സ്ഥിതിക്ക് അത് വേണ്ടെന്ന് വച്ചു.
അത് കൊണ്ട് പണ്ടൊരിക്കല് ഞാന് പറഞ്ഞ ഒരു സങ്കടം ആവര്ത്തിക്കുന്നു: “ഞാന് വായിച്ചവ” യില് കുറെ ചതുരക്കട്ടകള് മാത്രമേ കാണുന്നുള്ളൂ :(. മറ്റ് മലയാളം ബ്ളോഗുകള്ക്കോ, ഇതിലെ മറ്റ് പേജുകള്ക്കോ ഒരു കുഴപ്പവുമില്ല, താനും.
Operating System: Windows XP Professional
IE version: 6.00
അനില്_ANIL | 07-Feb-08 at 8:17 am | Permalink
യൂണിക്കോഡ് പ്രശ്നരാമായണം ബ്ലോഗ് പോസ്റ്റുകളായും ഗ്രൂപ്പ് ചര്ച്ചകളായും ഒരുപാട് വായിച്ചു മനസിലാക്കാന് ശ്രമിച്ച് മനം മടുത്തവര് വേറെയും ഉണ്ടോ എന്നറിയില്ല. എങ്ങും തൊടാതെ, ആരോപണങ്ങള്ക്കും അവഹേളനത്തിനും പ്രാമുഖ്യവും വസ്തുതകള് മനുഷ്യനു മനസിലാവുന്ന തരത്തില് അവതരിപ്പിക്കുന്നതില് വൈമുഖ്യവും മാത്രമായിരുന്നു അവിടങ്ങളിലൊക്കെയും എന്നത് പറയാതെ വയ്യ.
ഇഷ്ടമില്ലാത്ത അച്ചി തൊട്ടതെല്ലാം കുറ്റമാവുന്നതുകൊണ്ട് പലര്ക്കും ‘ഓഫ്ടോപ്പിക്ക് മിസൈലേറ്റ്’ ചാവാനാണ് വിധി. എന്തുകൊണ്ടാണ് അങ്ങനെ എന്ന് പലവട്ടം ആലോചിച്ചു പോയിട്ടുള്ളവര്ക്ക് മനസിലാവുന്ന മറുപടി ഈ പോസ്റ്റിന്റെ കമന്റുകളുടെ വരികള്ക്കിടയില് നിന്ന് വായിക്കാന് കഴിയുന്നുണ്ട്. അങ്ങനെയും ഈ പോസ്റ്റ് ഉപകാരപ്രദമാവുന്നുവെന്നു പറയാമെങ്കിലും എന്താണീ യൂണിക്കോഡ് വിവാദങ്ങളെന്ന് സാമാന്യ ജനത്തിനു മനസിലാക്കാനാവുമെന്നതു തന്നെയാണ് ഈ പോസ്റ്റുകൊണ്ടുണ്ടാവുന്ന പ്രധാന സഹായം.
ഈ വിഷയം എഴുതാന് മനസ്സുവച്ച ഉമേഷിന് ആയിരം നന്ദി.
പ്രവീണ് | 07-Feb-08 at 8:18 am | Permalink
ഞാന് ചോദിച്ച ചോദ്യങ്ങള് മനപ്പൂര്വ്വം ഒഴിവാക്കുകയാണോ? ഇനി ചോദ്യങ്ങളെ പേടിയാണോ? സിബുവും പലതവണ ചോദിച്ച ചോദ്യങ്ങളില് നിന്നുമൊഴിഞ്ഞു് മാറുകയാണു്.
പ്രവീണ് | 07-Feb-08 at 8:23 am | Permalink
വീണ്ടും വായിച്ചപ്പോള് ഉമേഷ്ജി അതിനെപ്പറ്റി പരാമര്ശിച്ചതു് കണ്ടു. ഇനി ആ ചോദ്യങ്ങള്ക്കുത്തരം പറഞ്ഞിട്ടേ അടുത്ത ചോദ്യമുള്ളൂ.
അനില്_ANIL | 07-Feb-08 at 8:24 am | Permalink
സ്വതന്ത്ര മലയാളം കമ്പ്യൂട്ടിങ്ങ് ആണവചില്ലിനെതിരെ UTC യ്ക്കു് സമര്പ്പിച്ച വാദങ്ങള് (http://images.wikia.com/fci/images/2/23/SMC_Unicode_5.1.pdf) വായിച്ചു. സായിപ്പന്മാരൊക്കെ വായിക്കേണ്ട ഒരു ലേഖനം അക്ഷരത്തെറ്റുകളും പ്രയോഗ വൈകല്യങ്ങളുമെങ്കിലും ഇല്ലാതെ എഴുതാമായിരുന്നു എന്ന ഒരു ഫ്രീ അഭിപ്രായമുണ്ട്.
P.C.Madhuraj | 07-Feb-08 at 12:55 pm | Permalink
My thanks to Umesh for correcting the vibhakthi name. But I am far from convinced about the need for struggling to write a non-malayalam word so as to describe the delicate difference in pronounciation. If at all required find some localised short-cuts-instead of generalising. Get rid of the chandrakkala- and write”Rahamaan”- will that practically solve the problem?
(I am sure, the CibumahaRshi, the inventor of varamozhi will solve these more appropriately!)
While suggesting that “vaRthsyanakaaram” need not be given a separate script, A.R(?) and others hoped that people will, by practice(bhaashaaparichayam) know how to pronounce “na”.(I know of some rules about this-ofcourse old ones, passed on from previous generation -and not necessarily to be followed by anyone today!)
…going far off from the topic.
As Sanjayan says, “peruththu salaam”.
സിബു | 07-Feb-08 at 4:15 pm | Permalink
കാനോനിക്കല് ഈക്വിവാലന്സ് എന്നാല് യുണിക്കോഡ് അക്ഷരങ്ങളുടെ രണ്ട് വ്യത്യസ്ത ശ്രേണികള് ഒരേകാര്യത്തെ ആണ് എപ്പോഴും കാണിക്കുക എന്നു സ്റ്റാന്റേഡില് എഴുതി വയ്ക്കുന്നതാണ്. യുണീക്കോഡിലെ ചരിത്രപരമായ തെറ്റുകള് തിരുത്താനുപയോഗിക്കുന്ന സംഗതിയാണ് പലപ്പോഴും ഇത്. മലയാളത്തില് ഇതിനുദാഹരണം: ഒ-എന്ന സ്വരത്തിന്റെ ചിഹ്നം = എ-യുടെ ചിഹ്നം + ആ-യുടെ ചിഹ്നം
യുണിക്കോഡ് പഴയചില്ലും പുതിയ ചില്ലും തമ്മില് കാനോനിക്കല് ഈക്വിവാലന്സ് കൊടുത്തിട്ടില്ല. zwj ഉള്ള ഒരു സീക്വന്സിന് അത് സാധ്യമാവും എന്ന് തോന്നുന്നില്ല.
ഭാവിയില്, ഇന്നത്തെ ചില്ലുകളെ, വ്യഞ്ജനം + ചന്ദ്രക്കല എന്നരീതിയില് സോര്ട്ട് ചെയ്യും. സെര്ച്ചിംഗിലും ഇങ്ങനെ തന്നെ. ഇപ്പോള് എഴുതപ്പെട്ടിരിക്കുന്ന ചില്ലുകളുടെ സ്ഥിതി എന്താവും എന്നതിനെ പറ്റി യുണീക്കോഡിന്റെ തീരുമാനം പറയാം:
– ഫോണ്ടുകള് zwj ഉപയോഗിക്കുന്ന ചില്ല് തുടര്ന്നും കാണിക്കുകയാണ് വേണ്ടത്
– ബാക്കിയുള്ള എല്ലാ അപ്ലിക്കേഷനുകളും പുതിയ ചില്ലുകളിലേയ്ക്ക് മാറണം. അതായത്, വരമൊഴി, കീമാന് തുടങ്ങിയവയെല്ലാം. zwjകളുടെ കാര്യത്തില് മലയാളത്തിനുവേണ്ടി ഇനിയൊരു എക്സപ്ഷന് ഉണ്ടാവില്ല. അതുകൊണ്ട് ഇനിയുള്ള ഡോക്യുമെന്റുകളില് പുതിയ ചില്ലുപയോഗിക്കുകയാണ് ബുദ്ധി.
എന്താണ് കൊലേഷന് എന്നല്ലേ പ്രവീണിന്റെ ചോദ്യമായിരുന്നത്? വാക്കുകളെ നിഘണ്ടുവിലെ ആകാരാദി ക്രമത്തില് അടുക്കുന്നതിനെയാണ് കൊലേഷന് എന്നുപറയുന്നത്. മലയാളത്തിലെ നിഘണ്ടുക്കളില് ചില്ലക്ഷരം എവിടെ വരണം എന്നതില് ഒരു ഏകസ്വഭാവം ഉണ്ടെന്ന് തോന്നുന്നില്ല. ചിലര് ചില്ലക്ഷരങ്ങളെ ഏറ്റവും ആദ്യം വയ്ക്കുന്നു. ചിലര് ചില്ലുള്ള വാക്കില് അതിന്റെ വ്യഞ്ജനം ഏതാണെന്നനുസരിച്ച് (ല് എന്നത് ല-യോ, ത-യോ ഒക്കെ ആവാം) ആ വ്യഞ്ജനത്തിന്റെ മറ്റുകൂട്ടക്ഷരങ്ങള്ക്കടുത്തുവയ്ക്കുന്നു. ‘അവന്‘ എന്നിങ്ങനെ ചന്ദ്രക്കലയില് അവസാനിക്കുന്നവയെ, പകുതി ഉ-ആയി പരിഗണിച്ച് ഉ-കാരത്തിനടുത്തുവയ്ക്കുന്നു. എന്നാല് ‘വാക്’ എന്നതില് കയുടെ ചില്ലാണ് എന്ന് പരിഗണിച്ച് അങ്ങനെ സോര്ട്ട് ചെയ്യുന്നു.
വ്യക്തിപരമായി കൊലേഷന് ഗ്രാഫിക്കല് (കാണുമ്പോളെങ്ങനെ) ആയിരിക്കണം – ഉച്ചാരണമോ ഉത്ഭവവ്യഞ്ജനമോ നോക്കിയിട്ടാവരുത് എന്നാണെന്റെ പക്ഷം. കാരണം നിഘണ്ടുനോക്കുന്നവന് വാക്കിന്റെ ഉത്ഭവവും ഉച്ചരണവും എന്താണെന്ന് ചിലപ്പോള് അറിയില്ലല്ലോ. ആ രീതിയില് ചില്ലിനെ ഒരു പ്രത്യേക അക്ഷരമായി പരിഗണിച്ച് സോര്ട്ട് ചെയ്യണം. മലയാളത്തിന്റെ ആകാരാദി ക്രമം എന്തായിരിക്കണം എന്നതിനെ പറ്റി ഒന്നോ രണ്ടോ ശക്തമായ പ്രപ്പോസലുകള് ഈ ചര്ച്ചകളില് നിന്നും ഉരുത്തിരിയാവുന്നതാണ്.
മധുരാജ്, റഹ്മാന് എന്നെഴുതേണ്ടതെങ്ങനെ എന്നത് ആദ്യം ജനങ്ങള് തീരുമാനിക്കേണ്ടതല്ലേ. മാത്രവുമല്ല, ഹ്മ, ഹ്മ, ഹമ എന്നൊക്കെഴുതാന് ഇന്നത്തെ വരമൊഴിയിലും കീമാനിലും വകുപ്പുണ്ടല്ലോ.
ഒരുകാര്യം കൂടി – വത്സ്യനകാരം ചേര്ക്കാനായി പ്രപ്പോസല് നിലവിലുണ്ട്. അതിനര്ത്ഥം എല്ലാവരും അതുപയോഗിച്ചു തുടങ്ങും/തുടങ്ങണം എന്നല്ല. വ്യാകരണപുസ്തകങ്ങളിലും ഗവേഷണപ്രബന്ധങ്ങളിലും രണ്ടു ‘ന’കളും തമ്മില് വേര്തിരിച്ച് കാണിക്കേണ്ടിവരുമ്പോള് ഉപയോഗിക്കാന് മാത്രം. രാജരാജവര്മ്മ മുതല് പലരും അതു് ഉപയോഗിച്ചിട്ടുണ്ടല്ലോ.
സന്തോഷ് തോട്ടിങ്ങല് | 07-Feb-08 at 5:05 pm | Permalink
സിബു ഉവാചഃ: വ്യക്തിപരമായി കൊലേഷന് ഗ്രാഫിക്കല് (കാണുമ്പോളെങ്ങനെ) ആയിരിക്കണം ഉച്ചാരണമോ ഉത്ഭവവ്യഞ്ജനമോ നോക്കിയിട്ടാവരുത് എന്നാണെന്റെ പക്ഷം. കാരണം നിഘണ്ടുനോക്കുന്നവന് വാക്കിന്റെ ഉത്ഭവവും ഉച്ചരണവും എന്താണെന്ന് ചിലപ്പോള് അറിയില്ലല്ലോ
എങ്കില് എന്റെ ഒരു പ്രൊപ്പോസലിതാ. സിബു ഇതല്ലേ ഉദ്ദേശിച്ചതു്? കാണാന് ഒരേ പോലെ ഇല്ലേന്നു നോക്കിക്കേ…നിഘണ്ടു നോക്കുന്നവനാണെങ്കില് എളുപ്പവും!
ച
പ
വ
ഖ
…
ന്
൯ (9)
ര്
൪ (4)
കയുടെ പരിസരത്തൊന്നും ഖ വന്നു പോകരുതു്!
സന്തോഷ് | 07-Feb-08 at 6:07 pm | Permalink
കൊലേഷന് ഗ്രാഫിക്കല് (കാണുമ്പോളെങ്ങനെ) ആയിരിക്കണം എന്നതിനോട് യോജിക്കാനാവുന്നില്ല. ഉച്ചാരണമായീരിക്കണം കൊലേഷന്റെ അടിസ്ഥാനം എന്നാണ് എന്റെ അഭിപ്രായം.
എന്നാലും സിബു പറഞ്ഞതിനെ സന്തോഷ് തോട്ടിങ്ങല് മുകളിലെഴുതിയതായി വ്യാഖ്യാനിക്കുന്നത് കടന്ന കയ്യാണ്.
Ralminov | 07-Feb-08 at 6:20 pm | Permalink
ഹ്മ എന്നു് എഴുതാന് പറ്റിയിട്ടെന്താ സിബു കാര്യം ? ഗൂഗ്ള് അതു് ഹ്മ എന്നാക്കില്ലേ . ചില്ലിനെ കൊല്ലുന്നതു് പോലെ. ഒരു പരിഹാരവും നിര്ദ്ദേശിച്ചും കണ്ടില്ല. വാട്ട് യു സീ ഈസ് വാട്ട് യു റൈറ്റ് എന്നതു് ചുരുങ്ങിയ പക്ഷം അതെഴുതുന്ന ആള്ക്കെങ്കിലും ലഭ്യമാക്കണ്ടേ .
സിബു | 07-Feb-08 at 7:25 pm | Permalink
എഴുതിയപ്പോള് ഞാനും അത്ര വിചാരിച്ചില്ലെങ്കിലും തോട്ടിങ്ങലിന്റെ ഐഡിയ മോശമൊന്നുമല്ല.
ആര്ക്കുവേണ്ടിയാണ് നിഘണ്ടുഎന്നതിനനുസരിച്ച് ക്രമവും മാറും. മലയാളം അക്ഷരങ്ങളെ പറ്റി വലിയ ഐഡിയ ഇല്ലാത്ത സായിപ്പിനാണെങ്കില് തോട്ടിങ്ങലിന്റെ ഓര്ഡര് മോശമല്ല.
മലയാളികള് ക-യ്ക്ക് ശേഷം ഖ പ്രതീക്ഷിക്കുന്നതുകൊണ്ട് അവര്ക്ക് അത് ശരിയാവില്ല. എന്നാല് ചില്ലുകള് എവിടെയാണ് ഒരു മലയാളി പ്രതീക്ഷിക്കുന്നത്? കൃത്യമായ ഒന്നില്ല എന്നതാണ് സത്യം. അപ്പോള് അതെവിടെ വേണം?
– ഉച്ചാരണപ്രകാരം ഏറ്റവും ആദ്യമോ
– ശബ്ദതാരാവലി ചെയ്യുമ്പോലെ ഉത്ഭവവ്യഞ്ജനത്തിന്റെ ആദ്യത്തെ കൂട്ടക്ഷരമായെടുത്ത് അതിനനുസരിച്ചോ (ശബ്ദതാരാവലിയില് ‘അവന്’ നോക്കുക)
സത്യത്തില് ശബ്ദതാരാവലിയിലേതിനേക്കാള് ഉച്ചാരണപ്രകാരം തരം തിരിക്കുന്നതിലേക്ക് ഞാന് ഇപ്പോള് ചായുന്നു.
ഉമേഷ് | Umesh | 07-Feb-08 at 10:48 pm | Permalink
അങ്കിള്,
(മൂന്നു കമന്റുകള്ക്കു് ഒന്നിച്ചു മറുപടി)
ഈ പോസ്റ്റെഴുതാന് എത്ര മണിക്കൂര് എടുത്തു എന്നതു് ഒരു വല്ലാത്ത ചോദ്യമാണു്. ഇതുപോലെ ഒരെണ്ണം എഴുതാന് ആലോചിച്ചു തുടങ്ങിയിട്ടു് ഒരുപാടു കാലമായി. ഈ പോസ്റ്റ് ഉണ്ടാക്കിയതു് ഒരാഴ്ച മുമ്പാണെന്നു തോന്നുന്നു. ഓരോ ദിവസവും അര-മുക്കാല് മണിക്കൂറില് കൂടുതല് സമയം ബ്ലോഗുകള് വായിക്കാനും എഴുതാനും ഒക്കെക്കൂടി കിട്ടിയിട്ടുമില്ല. പക്ഷേ, നേരത്തേ എഴുതിയ പല പോസ്റ്റുകളില് നിന്നും പലതും ഇതിലേക്കു് എടുത്തിട്ടുണ്ടു്. ടൈപ്പു ചെയ്താന് മൊത്തം 1-2 മണിക്കൂര് എടുത്തിട്ടുണ്ടാവണം. എന്നാല് ഇതിലെ കാര്യങ്ങള് ആലോചിച്ചെടുക്കാന് ഏതാനും മാസങ്ങളും.
അങ്കിള് ഉപയോഗിക്കുന്ന കീമാന് തന്നെയാണു ഞാനും ഉപയോഗിക്കുന്നതു്. വരമൊഴി, മലയാളം കീബോര്ഡ്, ഇളമൊഴി, മലയാളം ഓണ്ലൈന് തുടങ്ങിയവയും ഉപയോഗിച്ചിട്ടുണ്ടെങ്കിലും കീമാനാണു് ഇപ്പോള് പ്രധാനമായും ഉപയോഗിക്കുന്നതു്. ബ്ലോഗറല്ല, സര്വറില് ഇന്സ്റ്റാള് ചെയ്ത വേര്ഡ്പ്രെസ് ആണുപയോഗിക്കുന്നതു്. അതുകൊണ്ടു പോസ്റ്റ് പ്രിവ്യൂ തുടങ്ങിയവയ്ക്കു ചില സൌകര്യങ്ങളൊക്കെയുണ്ടു്.
പലപ്പോഴും ഉള്ളടക്കം നോട്ട്പാഡില് കീമാന് ഉപയോഗിച്ചു ടൈപ്പു ചെയ്തിട്ടു സൌകര്യം കിട്ടുമ്പോള് ബ്ലോഗിലേക്കു കോപ്പി ചെയ്യുന്നു. ഇന്റര്നെറ്റ് കണക്ഷനില്ലാത്തപ്പോഴും ഇതു ചെയ്യാം എന്നതാണു് ഒരു സൌകര്യം. മിക്കവാറും ദിവസങ്ങളില് ഓഫീസില് പോകുന്നതു ബസ്സിലായതിനാല് ബസ് സ്റ്റോപ്പിലിരുന്നു ടൈപ്പു ചെയ്യാന് പറ്റും. ഈ കമന്റു തന്നെ ഇന്നു രാവിലെ ബസ്സിനു കാത്തിരിക്കുമ്പോഴാണു മിക്കവാറും ടൈപ്പു ചെയ്തതു്. പോസ്റ്റു ചെയ്യുമ്പോഴേയ്ക്കും വൈകുന്നേരമാകും.
ഉള്ളടക്കം പലപ്പോഴായി ടൈപ്പു ചെയ്തിട്ടു് അവസാനം അതു് എഡിറ്റു ചെയ്യും. അതാണു വലിയ പണി. ഇങ്ങനെ ചെയ്യുന്നതു കൊണ്ടാവണം, എന്റെ പല പോസ്റ്റുകള്ക്കും ഏകാഗ്രത കുറവാണു്. പല തുണ്ടുകളെ ഇടയ്ക്കുള്ള വര കൊണ്ടു വേര്തിരിച്ചു പോസ്റ്റു ചെയ്യുന്ന ഒരേ ഒരാള് ഞാനാണെന്നു തോന്നുന്നു.
പ്ലാന് ചെയ്തെഴുതുന്ന ചില പോസ്റ്റുകള് ചിലപ്പോള് ഔട്ട്ലൈനിട്ടിട്ടു് ഉള്ളടക്കം പിന്നെ എഴുതുകയും ചെയ്യാറുണ്ടു്. പക്ഷേ, മിക്കപ്പോഴും തിരിച്ചാണു പതിവു്. അതിനെപ്പറ്റി തോന്നുന്ന കാര്യങ്ങള് ചുമ്മാ എഴുതും. അവസാനം എഡിറ്റു ചെയ്യും.
ശ്ലോകങ്ങള് തുടങ്ങി പ്രത്യേക ഫോണ്ടിലും നിറത്തിലും മറ്റും കാണുന്നവയ്ക്കു വേണ്ടി പ്രത്യേകം css span ടാഗുകള് ഉപയോഗിക്കുന്നു. അല്ലാതെ മാനുവലായി ഫോണ്ട് മാറ്റുന്നതല്ല. അതിനാല് എപ്പോല് വേണമെങ്കിലും ഒരു രീതി മാറ്റി മറ്റൊന്നാക്കാം. ഉദാഹരണമായി, എല്ലാ പോസ്റ്റിലെയും ശ്ലോകങ്ങളെ ഇനി മുതല് ചുവന്ന അക്ഷരത്തില് ഇറ്റാലിക്സില് കാണണമെങ്കില് എനിക്കു സെറ്റിംഗ്സില് രണ്ടു വരി മാറ്റിയാല് മതി.
ചില കാര്യങ്ങള് ചെയ്യാന് കുറേ ബുദ്ധിമുട്ടിയിട്ടുണ്ടു്. കമന്റുകളെ പിന്മൊഴിയിലും മറുമൊഴിയിലും വിടാന് കുറേ പണിപ്പെട്ടിട്ടുണ്ടു്. വിശദവിവരങ്ങള് ഇവിടെ. ഇപ്പോള് എങ്ങോട്ടും കമന്റുകളെ വിടുന്നില്ല.
ഇത്രയേ ഉള്ളൂ. ഇതൊന്നും രഹസ്യമല്ല. എന്തറിയണമെങ്കിലും പങ്കു വെയ്ക്കാന് സന്തോഷമേ ഉള്ളൂ.
സംവൃതോകാരത്തിനു് സിബു പറഞ്ഞ വഴി മതി. എനിക്കു് എന്നു കിട്ടാന് enikku~ എന്നു്. അതു വരമൊഴിയില് അങ്കിളിനു കിട്ടാത്തതു് ഒരു ബഗു മൂലമാണു്. ഒരു കൊല്ലത്തിനു മുമ്പു് ഞാന് അതു സിബുവിനോടു പറയുകയും സിബു അതു തിരുത്തുകയും ചെയ്തിരുന്നു. പക്ഷേ, അതിനു ശേഷം വരമൊഴിയ്ക്കു് ഒരു റിലീസ് ഉണ്ടാകാഞ്ഞതു കൊണ്ടു് ഏറ്റവും പുതിയ വരമൊഴി റിലീസ് ബൈനറിയിലും ആ ഫിക്സ് ഉണ്ടാവില്ല. സംവൃതോകാരം ഇങ്ങനെ എഴുതാന് അങ്കിളിനു് രണ്ടു കാര്യങ്ങളിലൊന്നു ചെയ്യാം.
1. വരമൊഴി പേജില് പോയി ആവശ്യമുള്ള ഫോണ്ടുകളുടെ ആഡ്-ഓണുകള് ഡൌണ്ലോഡു ചെയ്തു് അങ്കിളിന്റെ കമ്പ്യൂട്ടറിലെ വരമൊഴി ഇന്സ്റ്റലേഷന് ഡയറക്ടറിയില് ഇടുക. അങ്കിളിനു മാറ്റ്വെബ് (വലത്തുവശത്തു കാണാന്), യൂണിക്കോഡ് എന്നീ രണ്ടു് ആഡ്ഓണുകള് മതിയാകും. അതു് ഒന്നിച്ചൊരു സിപ് ഫയല് ആയി ആണുള്ളതു്. ആവശ്യമുള്ള ഫയലുകള് മാത്രം എടുത്താല് മതി.
2. അല്ലെങ്കില് enikku~ എന്നതിനു പകരം enikku_~ എന്നു ടൈപ്പു ചെയ്താല് മതി. ഞാന് കണ്ടുപിടിച്ച ഒരു വഴിയാണു്.
വരമൊഴി ഉപയോഗിക്കുന്നവരില് ഞാനല്ലാതെ ആരും സംവൃതോകാരം ഇങ്ങനെ എഴുതുന്നില്ല എന്നു തോന്നുന്നു. അതുകൊണ്ടാവണം സിബു ഇതുള്പ്പെടുത്തി ഒരു റിലീസ് ഇറക്കാഞ്ഞതു് 🙂 കീമാനില് ഈ പ്രശ്നമില്ല. enikku~ എന്നു ടൈപ്പു ചെയ്താല് മതി.
ഇതിനെപ്പറ്റി കൂടുതല് കാര്യങ്ങള് സിബുവിനോടു നേരിട്ടോ അല്ലെങ്കില് വരമൊഴി യാഹൂ ഗ്രൂപ്പില് ചേര്ന്നു് അവിടെയോ ചോദിക്കുക.
അങ്കിള് “ഈ പോസ്റ്റെഴുതാന് ഉമേഷ് എത്ര മണിക്കൂര് എടുത്തിരിക്കും? വേറെ ചില കാര്യങ്ങള്ക്കുത്തരം കിട്ടാനാണേ…” എന്നെഴുതിയതു കണ്ടു. ഈ “വേറേ ചില കാര്യങ്ങള്” എന്താനെന്നറിയാന് ആഗ്രഹമുണ്ടു്. അവയ്ക്കു് ഉത്തരം കിട്ടിയോ?
സന്തോഷ് തോട്ടിങ്ങല് | 08-Feb-08 at 3:41 am | Permalink
“എഴുതിയപ്പോള് ഞാനും അത്ര വിചാരിച്ചില്ലെങ്കിലും തോട്ടിങ്ങലിന്റെ ഐഡിയ മോശമൊന്നുമല്ല.
ആര്ക്കുവേണ്ടിയാണ് നിഘണ്ടുഎന്നതിനനുസരിച്ച് ക്രമവും മാറും. മലയാളം അക്ഷരങ്ങളെ പറ്റി വലിയ ഐഡിയ ഇല്ലാത്ത സായിപ്പിനാണെങ്കില് തോട്ടിങ്ങലിന്റെ ഓര്ഡര് മോശമല്ല.”
തോട്ടിങ്ങലിന്റെ ഓര്ഡറോ?! പറഞ്ഞു് പറഞ്ഞു് അതു് എന്റെ ഓര്ഡറാക്കല്ലേ പ്ലീസ്.. 🙂
സിബു പറഞ്ഞ പ്രകാരം കുറച്ചു അക്ഷരങ്ങളെഴുതിനോക്കി എന്നൊരപരാധമേ ഞാന് ചെയ്തുള്ളൂ! സോറി…!
പിന്നെ ഇതു വായിക്കുന്നവരാരെങ്കിലും സ്വനലേഖ ഉപയോഗിക്കുന്നുണ്ടെങ്കില് അവരുടെ അറിവിലേക്കു്: എഴുതിക്കൊണ്ടിരിക്കുമ്പോള് ആവശ്യമുള്ള സ്ഥലങ്ങളില് സംവൃതോകാരം കഴ്സറിനടിയില് മെനുവില് സജഷനായി വരും.
സജഷന് മെനു ഉപയോഗിക്കുന്നുല്ലെങ്കില് u^ എന്നും ഉപയോഗിക്കാം. ഉദാഹരണം: അതു്= athu^
അങ്കിള് | 08-Feb-08 at 5:18 am | Permalink
പ്രിയ ഉമേഷ്,
ആ അദ്ധ്യാപികയുടെ സര്വ്വ ഗുണങ്ങളും പകര്ന്നുകിട്ടിയതു കാണുമ്പോള് എന്തെന്നില്ലാത്ത സന്തോഷം.
ഇത്രയും നീണ്ട മറുപടിയെഴുതിയതിനു നന്ദി. എന്റെ സംശയങ്ങളെല്ലാം മാറി.
ഉമേഷെഴുതൂന്ന ലേഖനങ്ങളും അതിലെ ലിങ്കുകളും അതിലുള്പെടുത്തുന്ന മറ്റു കാര്യങ്ങളെല്ലാം കണ്ടപ്പോള് out of office hours ചെയ്തു തീര്ക്കാന് കഴിയുന്ന ഒരു കാര്യങ്ങളാണതെന്ന് സ്വപനത്തില് പോലും ഞാന് കരുതിയില്ല. അതുകൊണ്ട് ഓഫീസിലും ഈ മലയാളം പണി തന്നെയായിരിക്കുമെന്ന ഒരു ദുര്ഃചിന്ത എന്റെ മനസ്സിലുണ്ടായിരുന്നു. എന്റെ പ്രായം കണക്കിലെടുത്ത് തിരിച്ച് ചീത്ത വിളിക്കില്ലെന്ന ധൈര്യമാണ് അതെഴുതാന് പ്രേരിപ്പിച്ചത്. ഞാനെടുത്ത സ്വാതന്ത്ര്യം അതിരു കടന്നു പോയോ എന്തോ.
വളരെ സീരിയസ്സായി ഇവിടെ വരുന്ന വായനക്കാര്ക്ക് ഈ കമന്റ് ഒന്ന് നെടുവീര്പ്പിടാനുള്ള സ്ഥലമായി കാണടണേയെന്നാശിക്കുന്നു.
പ്രവീണ് | 08-Feb-08 at 7:28 am | Permalink
ഉമേഷ്ജി കൊലേഷനെന്താണെന്നിതു് വരെ പറഞ്ഞില്ല. പറയാതെ ഒഴിഞ്ഞു് മാറാനാണോ ഭാവമെന്നറിയില്ല. സിബു പറഞ്ഞതു് കൊണ്ടായില്ല. ഉമേഷ്ജി എന്തായാലും കോണ്ടസ വിശദീകരിയ്ക്കാനിറങ്ങിയിട്ടു് ഇത്രയും പ്രധാനപ്പെട്ടൊരു കാര്യം ഒഴിവാക്കുന്നതു് മനസ്സിലാകുന്നില്ല.
Umesh:ഉമേഷ് | 08-Feb-08 at 10:18 am | Permalink
പ്രവീണ്,
കൊലേഷനെപ്പറ്റി എഴുതാം. ടെക്നിക്കല് ജാര്ഗണ് പറയാതെ ഇതു വായിക്കുന്നവര്ക്കു മനസ്സിലാവുന്ന രീതിയില് മലയാളത്തിലെ അക്ഷരമാലാക്രമത്തെപ്പറ്റിയും അതെങ്ങനെ ചെയ്യാന് കഴിയും എന്നതിനെപ്പറ്റിയും എഴുതാം. അതാണു് എന്റെ ലക്ഷ്യം. ടെക്നിക്കല് കാര്യങ്ങള് പറഞ്ഞു വാദിക്കാന് ഇവിടെ സിബുവും സുരേഷും സന്തോഷുമുണ്ടല്ലോ.
അതെന്താ സിബു പറഞ്ഞതു കൊണ്ടാകാത്തതു്? ചോദിക്കുന്നതിന്റെ ഉത്തരം കിട്ടുന്നില്ലേ? അതോ, മഹേഷ് പൈയോടെന്ന പോലെ “നിന്നോടു പറഞ്ഞിട്ടു കാര്യമില്ല” എന്നാണോ സിബുവിനോടുമുള്ള മനോഭാവം?
ഞാന് തത്ക്കാലം രണ്ടു കൂട്ടരും പറയുന്നതു കേള്ക്കട്ടേ. ഇന്ഡിക് ഗ്രൂപ്പില് വായിച്ചിട്ടില്ലെന്നല്ല. അവിടെ ഒരു ടണ് തെറി സ്കാന് ചെയ്തെങ്കിലേ ഒരു ഗ്രാം വിജ്ഞാനം കിട്ടുമായിരുന്നുള്ളൂ. അതിനാല് പലതും വിട്ടുപോയിട്ടുണ്ടു്.
ആണവചില്ലുകൊണ്ടു് കോലേഷന് അസാദ്ധ്യമാകും എന്നെനിക്കു തോന്നിയിട്ടില്ല.
ഇതു മനസ്സിലാകാത്തവര്ക്കു വേണ്ടി: വാക്കുകളെ അക്ഷരമാലാക്രമത്തില് അടുക്കാന് വേണ്ട നിയമങ്ങളുടെ സമുച്ചയമാണു കൊളേഷന്. ഇതു യൂണിക്കോഡില് മലയാളത്തിനു വേണ്ടി എഴുതേണ്ടതുണ്ടു്. ഇപ്പോഴുള്ളതു പോരാ. ഉദാഹരണമായി, റ എന്നതു ലയ്ക്കു മുമ്പു വരാതെ അവസാനം വരണം. അതു പോലെ ചില്ലക്ഷരങ്ങളും വരേണ്ട സ്ഥലത്തു വരണം. അറ്റോമിക് ചില്ലു വന്നാല് ഇതു പറ്റാതെ വരും എന്നാണു പ്രവീണ് പറയുന്നതു്. അല്ല എന്നതാണു വാസ്തവം.
Umesh:ഉമേഷ് | 08-Feb-08 at 10:24 am | Permalink
അങ്കിള്,
ഏതു് അദ്ധ്യാപിക? കണ്ഫ്യൂഷനായല്ലോ 🙂
പിന്നെ, ഓഫീസ് സമയത്തു ബ്ലോഗുമായി ബന്ധപ്പെട്ട കാര്യങ്ങള് ചെയ്യുന്നില്ല എന്നു പറയാന് പറ്റില്ല. പല കമന്റുകളും മെയിലില് വായിക്കുന്നതും എന്റെ ബ്ലോഗിലെ പല കമന്റുകളുടെയും ചെറിയ മറുപടികള് എഴുതുകയും ചെയ്യുന്നതു് ഓഫീസ് സമയത്താണു്. ബില്ല് പേ ചെയ്യുക തുടങ്ങിയ പല പേഴ്സണല് കാര്യങ്ങളും ഓഫീസിലിരുന്നു ചെയ്യാറുണ്ടു്. അതേ സമയം ഓഫീസ് ജോലി വീട്ടിലിരുന്നും ഒരുപാടു ചെയ്യാറുണ്ടു്. മിക്കവാറും സോഫ്റ്റ്വെയര് എഞ്ചിനീയര്മാരുടെയും സ്ഥിതി ഇതാണെന്നു തോന്നുന്നു.
സന്തോഷ് തോട്ടിങ്ങല് | 08-Feb-08 at 10:51 am | Permalink
അവിടെ ഒരു ടണ് തെറി സ്കാന് ചെയ്തെങ്കിലേ ഒരു ഗ്രാം വിജ്ഞാനം കിട്ടുമായിരുന്നുള്ളൂ.
അങ്ങനെയാണോ അല്ലയോ എന്നു് നോക്കണമെങ്കില് ഈ പോസ്റ്റിന്റെ ആദ്യത്തെ കമന്റില് കൊടുത്ത ലിങ്കില് പോയി ആര്ക്കും വായിച്ചു നോക്കാം.
ഉമേഷ്ജീ, ദയവായി ആളുകളെ തെറ്റിദ്ധരിപ്പിക്കാതിരിക്കൂ… മോഡറേറ്ററില്ലാത്ത ലിസ്റ്റൊന്നുമല്ല അതു് ,
അനിവര് | 08-Feb-08 at 11:54 am | Permalink
ആണവചില്ലിനെക്കുറിച്ച് ഞാനൊരു പോസ്റ്റ് എഴുതുന്നുണ്ട്. ഇപ്പോ ഇതിന്റെ തിരക്കിലാ.. ഒന്നു തീര്ന്നോട്ടെ
അനിവര്
Ralminov | 08-Feb-08 at 12:46 pm | Permalink
ഉമേഷ് നല്കിയ യാഹൂ എമ്മെസ്സെന് സ്കാന് ഇപ്പഴാണു് ശ്രദ്ധിച്ചതു്. അവയില് അവന് അല്ലാത്ത ചില്ലുകളും കാണുന്നില്ലേ ?
ഉദാ: ആദ്യ സേര്ച്ച് റിസല്ട്ട് .
യാഹൂ : കര്മ്മങ്ങളുടെ ശ്രേഷ്ഠതകള് : രണ്ടു് ചില്ലുകള് നല്ല വൃത്തിയായി കാണാം.
എമ്മെസ്സെന് : പ്രസാദം ലഭിപ്പാന് ….പാപം ചെയ്താല് ….
ഇതൊക്കെ ചില്ല് തന്നെയല്ലേ.
ഗൂഗ്ളിന്റെ വിവരക്കേടു് തിരുത്തേണ്ടതല്ലേ…
suresh | 08-Feb-08 at 1:08 pm | Permalink
“ഗൂഗ്ളിന്റെ വിവരക്കേടു് തിരുത്തേണ്ടതല്ലേ… ”
ഒരു പക്ഷെ ആണവചില്ലു് വന്നാല് ഉണ്ടായേക്കാവുന്ന ഒരു നല്ലകാര്യം ഗൂഗ്ള് പിന്നീടു് തിരുത്തപ്പെടുന്നതു് ആയിരിക്കും.അതുവരെ വെട്ടിമുറി ഫലം തന്നെയായിരിക്കും എന്നു പ്രതീക്ഷിക്കാം.
Ralminov | 08-Feb-08 at 1:29 pm | Permalink
യാഹൂവിന്റെ ബഗ് പിടികിട്ടി. സേര്ച്ച് ചെയ്യുന്ന വാക്കിന്റെ റെന്ഡറിങ്ങിനു് മാത്രമാണു് കുഴപ്പം. അതു് ചിലപ്പോള് ബോള്ഡ് കൊടുക്കുന്നതു് കൊണ്ടോ സ്റ്റൈല് മാറ്റം കൊണ്ടോ ആയിരിക്കും.
അതു് റിപ്പോര്ട്ട് ചെയ്തു് മാറ്റിക്കണം.
അങ്കിള് | 08-Feb-08 at 2:39 pm | Permalink
പിന്നെയും എന്നെകൊണ്ട് ഓഫിടാന് നിര്ബന്ധിതനാക്കുന്നു.
ഒരദ്ധ്യാപികയുടെ മകന്നാണെന്ന് വായിച്ചതായരോര്മ്മ വച്ച് കാച്ചിയതാണ്. ബ്ലോഗ് തുടങ്ങിയപ്പോള് വായിച്ചതായിട്ടാണോര്മ്മ. ഇപ്പോള് പ്രൊഫൈല് തപ്പിയപ്പോള് ആങ്ങനെയൊരു വിവരം കാണുന്നുമില്ല. എന്തു ചെയ്യാന് എന്റീശ്വൊരാ… എന്റെ തള്ളക്ക് വിളിച്ചുന്ന് ആരോപിക്കല്ലേ. ഉദ്ദേശ ശുദ്ധി, ഉദ്ദേശ ശുദ്ധി.
ഓഫീസ്സിലിരുന്ന് ബ്ലോഗും എന്ന് വെളിപ്പെടുത്തുമെന്ന് ഞാന് ഒട്ടും പ്രതീക്ഷിച്ചില്ല. ബൂലോഗര് കുറച്ചുകൂടെ ആത്മാര്ത്ഥത കാട്ടി കൂടേ എന്നൊരു പോസ്റ്റ് ഞാന് ഇട്ടിരുന്നു കുറച്ചു നാള് മുമ്പ്. എന്തുകൊണ്ട് ഒരു ബ്ലോഗര് അവരുടെ പ്രൊഫൈലില് തന്നെപറ്റിയുള്ള യതാര്ത്ഥവിവരങ്ങള് രേഖപ്പെടുത്തുന്നില്ല എന്നുള്ളതായിരുന്നു എന്റെ പരാതി. ഒരാളു പോലും എന്നോടു യോജിച്ചില്ല. ഓഫീസിലിരുന്ന് മേലധികാരികള് അറിയാതെയാണ് ബ്ലോഗുന്നതെന്നുള്ള ഒരു തോന്നലാണ് പ്രതികരണങ്ങളില് നിന്നെനിക്ക് കിട്ടിയത്. അമേരിക്കയിലുള്ളതും മറ്റിടങ്ങളിലുള്ളതുമായ പ്രവാസികളുടെ വിത്യാസം ഇപ്പോള് ഞാന് മനസ്സിലാക്കുന്നു.
അപ്പോള് ‘ആ അദ്ധ്യാപികയുടെ’ എന്നതു ‘ഒരദ്ധ്യാപകന്റെ’ എന്നായി മാറ്റി വായിക്കുമല്ലോ.
സിബു | 08-Feb-08 at 4:03 pm | Permalink
ദേ പിന്നേയും ഗൂഗിളിന്റെ ബഗ് യാഹൂവിന്റെ സ്റ്റൈല് ഷീറ്റ് എന്നിങ്ങനെ പറഞ്ഞ് വന്നിരിക്കുന്നു… കുറച്ചുമുമ്പിലെഴുതിയ കമന്റ് താഴെ കോപ്പി പേസ്റ്റ് ചെയ്യണോ. അതിനിടയില് ഒരുളുപ്പുമില്ലാതെ ചിലര് സിനിമാപരസ്യം ഇടുന്നു.
Ralminov | 08-Feb-08 at 5:24 pm | Permalink
സിബൂ, അസഹ്യമായി ഞാനെന്തെങ്കിലും പറഞ്ഞില്ലല്ലോ. ചില്ല് വന്നാലുമില്ലെങ്കിലും ജോയ്നറുകള് തള്ളുന്ന വിവരക്കേടു് തിരുത്തുക തന്നെ വേണം. ജീമെയിലില് തിരുത്തിയതു് പോലെ.
പരിഹാരം നിര്ദ്ദേശിക്കുന്നവരെ പരിഹസിക്കുന്നവരോടു് എന്തു് പറയാന് .
ഇനി “വിവരക്കേടു്” എന്ന വാക്കിലാണു് പ്രശ്നമെങ്കില് “വിവരക്കൂടുതല്” എന്നു് തിരുത്തിവായിക്കാനപേക്ഷ.
സന്തോഷ് തോട്ടിങ്ങല് | 08-Feb-08 at 5:25 pm | Permalink
ഉമേഷ്ജീ,
ഈ ചര്ച്ച എവിടേയ്ക്കാ പോകുന്നതു്?
ഇതെവിടെയും എത്തുന്ന ലക്ഷണമില്ല. 🙁
കമന്റുകള് മോഡറേറ്റു ചെയ്യുന്നതായിരിക്കും നല്ലതെന്നു് തോന്നുന്നു. ഉമേഷ്ജിയുടെ ഇഷ്ടം.
Umesh:ഉമേഷ് | 08-Feb-08 at 6:17 pm | Permalink
അങ്കിള്,
പേഴ്സണല് ഈമെയില് വായിക്കുന്നതിന്റെ കൂടെ ഞാന് കമന്റുകള് സബ്സ്ക്രൈബ് ചെയ്തിരിക്കുന്ന പോസ്റ്റുകളുടെ കമന്റുകളും വായിക്കും, വളരെക്കുറച്ചു മാത്രമേ ഉള്ളെങ്കില് മറുപടിയും കമന്റായി അവിടെ നിന്നു തന്നെ ഇടും എന്നു പറഞ്ഞതിനെ “ഓഫീസിലിരുന്നു ബ്ലോഗും എന്നു വെളിപ്പെടുത്തി” എന്നൊരു ഭാഷ്യം ചമയ്ക്കും എന്നു ഞാന് കരുതിയില്ല.
ഞാന് ഓഫീസിലിരുന്നു ബ്ലോഗ് ചെയ്യാറില്ല. ഓഫീസ് ക്ഌപ്തസമയം എന്നൊരു സാധനം ഞങ്ങള്ക്കില്ല. എട്ടൊമ്പതു മണിക്കൂര് ഓഫീസിലുണ്ടാവും. പിന്നെ വീട്ടില് ചെന്നിട്ടു മൂന്നു നാലു മണിക്കൂറും ജോലി ചെയ്യും. ഈ പത്തുപന്ത്രണ്ടു മണിക്കൂറില് രണ്ടു മൂന്നു മണിക്കൂര് വ്യക്തിപരമായ കാര്യങ്ങള്ക്കു (ബ്ലോഗിംഗ് അല്ല) ചെലവാക്കാറുണ്ടു്. ഡോക്ടറെ കാണാനോ മറ്റോ പോകണമെങ്കില് ഓഫീസില് നിന്നിറങ്ങി പോകാറുമുണ്ടു്. മറ്റു കാര്യങ്ങള്ക്കു ഓഫീസില് ചെലവാക്കുന്ന സമയം മറ്റെപ്പോഴെങ്കിലും നികത്താറുമുണ്ടു്. അല്ലാതെ സെക്രട്ടേറിയേറ്റില് ജോലി ചെയ്യുന്ന സമയത്തു ട്യൂട്ടോറിയല് കോളെജില് പഠിപ്പിക്കുന്നതു പോലെയല്ല.
അങ്കിളിന്റെ കമന്റ് ഓഫീസില് വന്നു മെയില് വായിച്ചപ്പോള് കണ്ടു. അതിനാല് ഈ കമന്റ് ഓഫീസില് നിന്നു് ഇടുന്നു. എന്നാല് അങ്കിള് ആ പോസ്റ്റില് പരഞ്ഞ കാര്യത്തിനോടു വിയോജിപ്പുണ്ടു്. അതെഴുതാന് കൂടുതല് സമയം വേണം. അതു് അങ്കിളിന്റെ പോസ്റ്റില് കമന്റായി സമയം കിട്ടുമ്പോള് ഇടാം.
Umesh:ഉമേഷ് | 08-Feb-08 at 6:23 pm | Permalink
കോവാലകൃഷ്ണാ,
ഓഫ്ടോപ്പിക് കമന്റുകള് ഡിലീറ്റ് ചെയ്യുമെന്നു പറഞ്ഞിട്ടില്ല. അലമ്പുണ്ടാക്കുന്ന അനാവശ്യകമന്റുകള് കളയും എന്നേ പറഞ്ഞുള്ളൂ. അതു കൊണ്ടു തന്നെ കോവാലകൃഷ്ണന്റെ അവസാനത്തെ കമന്റ് ഡിലീറ്റ് ചെയ്യുന്നു.
കോവാലകൃഷ്ണന്റെ പഴയ കമന്റും ഡിലീറ്റ് ചെയ്യണമെന്നു കരുതിയതാണു്. എന്നാല് അതിനു പ്രവീണ് കൊടുത്ത മറുപടിയോടു് എനിക്കു പൂര്ണ്ണയോജിപ്പുള്ളതു കൊണ്ടു മാത്രമാണു് രണ്ടും കിടക്കട്ടേ എന്നു വിചാരിച്ചതു്.
അതൊഴികെയുള്ള കോവാലന് കമന്റുകളും അതിനു പ്രവീണും ഞാനും അനിവറും കൊടുത്ത കമന്റുകളും ഡിലീറ്റ് ചെയ്യുന്നു.
സന്തോഷ് അവസാനം പറഞ്ഞതിനോടു യോജിക്കുന്നു. എന്നാലും മോഡറേറ്റു ചെയ്യാന് ഉദ്ദേശിക്കുന്നില്ല. അനാവശ്യമായതു ഡിലീറ്റ് ചെയ്തേക്കാം.
viswam | 08-Feb-08 at 6:59 pm | Permalink
വളരെക്കാലമ് കാത്തുകാത്തിരുന്ന, വളരെ പ്രധാനപ്പെട്ടതെന്നു വിചാരിക്കുന്ന ഒരു വിഷയമാണ് അതിന് ഏറ്റവുമ് യോജിച്ച ഒരു വേദിയില് (സ്വന്തമ് പോസ്റ്റുകള്ക്കു് കൃത്യതയുമ് അതിനുവരുന്ന കമന്റുകള്ക്ക് വിഷയപ്രതിബദ്ധതയും വേണമെന്നു നിര്ബന്ധമുള്ള, വ്യക്തിപരിചയങ്ങളേക്കാള് വസ്തുനിഷ്ഠതയ്ക്ക് പ്രാധാന്യമ് കൊടുക്കുന്ന ഒരാളുടെ ബ്ലോഗില്) ഇപ്പോള് എത്തിപ്പെട്ടിരിക്കുന്നത്. അതുകൊണ്ടുതന്നെ ഫോക്കസ് ഒട്ടുമ് കുറയാതെ ഓഫ്-ടോപ്പിക്കുകള് പരമാവധി കുറച്ച് വ്യക്തിഗതമായ മുന്നിഷ്ടങ്ങളുമ് പരിഹാസവുമ് പരമാവധി ഒഴിവാക്കി എല്ലാവരുമ് സഹകരിക്കുമെന്ന് പ്രത്യാശിക്കട്ടെ. പ്രത്യേകിച്ച് കാതലൊന്നുമില്ലെങ്കില് / വെറുമൊരു രസത്തിനുവേണ്ടിയുള്ള കമന്റുകള് ഇടാതെ എല്ലാര്ക്കുമ് കുറച്ച് സ്വയമ്നിയന്ത്രണമ് ആകാമ്.
ബഹുമാനപ്പെട്ട അങ്കിള് ആത്മാര്ത്ഥമായിട്ടുമ് നിഷ്കളങ്കമായിട്ടുമ് ആയിരിക്കാമ് അദ്ദേഹത്തിന്റെ സമ്ശയങ്ങള് ചോദിച്ചിട്ടുണ്ടാവുക. എങ്കിലുമ് അത്തരമ് ചോദ്യങ്ങള് നേരിട്ട് ഈ-മെയിലിലോ അല്ലെങ്കില് അതിന് അനുയോജ്യമായ മറ്റു പോസ്റ്റുകളിലോ ഫോറങ്ങളിലോ ചോദിക്കുന്നതാവില്ലേ നല്ലത്?
അജ്ഞാതനായ കോവാലകൃഷ്ണാ, ഇത്തരമ് കാര്യങ്ങളൊക്കെ (വ്യക്ത്യധിഷ്ഠിതപ്രശ്നങ്ങളൊക്കെ) വേറൊരു സന്ദര്ഭത്തില് വേറൊരു വേദിയില് ആയിക്കൂടേ? ഇവിടെ കാര്യമാത്രപ്രസക്തമായി മാത്രമ് നമുക്കൊക്കെ ഇടപെടാന് ശ്രമിച്ചുകൂടേ?
ഈ ചര്ച്ചയോട് കുറച്ചെങ്കിലുമ് ബഹുമാനമുണ്ടെങ്കില് പ്രത്യേകിച്ച് യാതൊരുവിധ ഉപകാരവുമില്ലാത്ത ലിങ്കുകളിലേക്കുമ് പേജുകളിലേക്കുമ് തങ്ങളുടെ കമന്റുകള് കൊളുത്തിവലിക്കാതിരിക്കാനുമ് ശ്രദ്ധിക്കണേ സുഹൃത്തുക്കളേ.
വിഷയത്തിലൂന്നിത്തന്നെ പലതുമ് പറയാനുണ്ടെന്ന് എനിക്കുമ് സ്വയമ് തോന്നുന്നുണ്ട്. എഴുതുന്നതെന്താണെന്നതിനേക്കാള് എഴുതുന്നതാരാണ് എന്ന് കൂടുതല് വിചാരപ്പെടുന്ന ആളുകള്ക്ക് ചര്ച്ചയുടെ വഴിതെറ്റിക്കാന് ഒരു പിടിവള്ളി കൊടുക്കണ്ടല്ലോ എന്നുമാത്രമ് കരുതി, കഴിയാവുന്നത്ര മൌനമ് പാലിച്ച് എങ്കിലുമ് പരമാവധി ശ്രദ്ധിച്ച് ഇവിടെ കൂടിയിരിക്കുകയാണ്.
വിനീതമായ ഒരഭ്യര്ത്ഥനയായി ഈ കമന്റിനെ എല്ലാവരുമ് വായിക്കാന് അഭ്യര്ത്ഥന.
കൂട്ടത്തില് ഒരു സമ്ശയമ്:
(അനുസ്വാരത്തിന് എന്തേ ഈ വക പ്രശ്നങ്ങളൊന്നുമില്ലാത്തത്?)
suresh | 09-Feb-08 at 2:31 am | Permalink
വ്യത്യസ്ത ഐഡികള് ഉപയോഗിക്കുമ്പോള് പ്രത്യേകം സ്റ്റൈല് ഉപയോഗിക്കുന്നതു് നന്നായിരിക്കും എന്നൊരറിവു് എന്തായാലും ഇവിടെ നിന്നും കിട്ടി. 🙂
നന്ദി.
sajith | 09-Feb-08 at 5:50 am | Permalink
ഹാവൂ. ഒരാളെങ്കിലും ചീത്ത വിളിയും ബഹളവുമില്ലാതെ എന്താ സംഭവം എന്നു വിശദീകരിച്ചല്ലൊ. വളരെ സന്തോഷം, വളരെ നന്ദി!
പ്രവീണ് | 09-Feb-08 at 6:16 am | Permalink
ഉമേഷ്ജി ആ കമന്റിലിട്ടത്രേം വിശദീകരണമേ ഞാനും പ്രതീക്ഷിച്ചുള്ളൂ. സിബുവിനു് പറയാനുള്ളതു് പലതും കേട്ടതല്ലേ. ഇതേ ചോദ്യം പലവട്ടം ചോദിച്ചിട്ടുമുണ്ടു്. ഉമേഷ്ജി ആളുകള്ക്കു് മനസ്സിലാകുന്ന രീതിയിലീ ലേഖനമെഴുതിയതു് കൊണ്ടു് അടിസ്ഥാനപരമായ ചില കാര്യങ്ങള് മനസ്സിലാക്കിയിരിയ്ക്കുന്നതെങ്ങനെയാണെന്നറിയാനാണു്. സിബുവുമായി തുടങ്ങിയാലിതിവിടെയൊന്നും നില്ക്കില്ല. ആ ചോദ്യം അടുത്ത ചോദ്യത്തിനുള്ള വഴിയൊരുക്കാനായിരുന്നു. അടുത്ത ചോദ്യമിതാ. കൊളേഷന് വെയിറ്റ് എന്നാലെന്താണു്?
(എല്ലാം കൂടി ഒന്നിച്ചു് ചോദിച്ചാല് ഇതു് വീണ്ടും എവിടെയുമെത്താത്ത അവസ്ഥയിലാകും എന്നതു് കൊണ്ടാണു് ഓരോന്നോരോന്നായി ചോദിയ്ക്കുന്നതു്)
സിബു | 11-Feb-08 at 7:05 pm | Permalink
ന് < ന < നാ < … < നൌ = നൗ < നു് = ന് < ന്ത …
എന്ന ആകാരാദിക്രമത്തെപറ്റി എന്തുപറയുന്നു? വേറേ ക്രമങ്ങളെന്തെങ്കിലും മനസ്സില് വരുന്നുണ്ടോ?
സന്തോഷ് തോട്ടിങ്ങല് | 12-Feb-08 at 6:51 am | Permalink
ആകാരമല്ല സിബൂ, അകാരാദിക്രമം. ‘ആകാരം‘ സിബു ഇനീം വിട്ടില്ലേ :). സിബുവിന്റെ ഓര്ഡറിനെപ്പറ്റി ആലോചിച്ചു പറയാം.
സന്തോഷ് തോട്ടിങ്ങല് | 12-Feb-08 at 8:37 am | Permalink
വിശ്വപ്രഭയുടെ കമന്റു കണ്ടപ്പോള് ഒരു സംശയം:
മ് എന്നോ മു് എന്നോ അവസാനിക്കുന്ന മലയാളം വാക്കുകള് ആര്ക്കെങ്കിലും അറിയുമെങ്കില് പറഞ്ഞുതരാമോ? വെറുതെ അറിഞ്ഞിരിക്കാനാണു്.
സിബു | 12-Feb-08 at 6:17 pm | Permalink
നന്ദി സന്തോഷ്.. അങ്ങനെ ഒരു വാക്ക് കേട്ട് പരിചയമുള്ളതുകൊണ്ടെഴുതിയതാണ്. ഇപ്പോ ശരിക്കുള്ള സ്പെല്ലിംഗ് മനസ്സിലായി 🙂
സദ്വാരം/സദ്വാരം, വന്യവനിക/വന്യവനിക എന്നീ ജോടികളില് അര്ഥവ്യത്യാസമില്ല എന്ന ഉമേഷിന്റെ വാദം ശരിയല്ല.
സദ്വാരം = നല്ല വാരം, നല്ല ദ്വാരം
സദ്വാരം = നല്ല വാരം
‘നല്ല ദ്വാരം’ എന്ന അര്ഥത്തില് ‘സദ്വാരം’ ഉപയോഗിക്കാന് പറ്റില്ല എന്നതുകൊണ്ട് തന്നെ സദ്വാരവും സദ്വാരവും തമ്മില് അര്ഥവ്യത്യാസമുണ്ട്.
സിബു | 12-Feb-08 at 6:20 pm | Permalink
ഉമേഷ് തിരുത്തിത്തന്നത്:
സദ്വാരം എന്നാല് ‘നല്ലദ്വാരം’ എന്നല്ല അര്ഥം. ‘ദ്വാരത്തോട് കൂടിയത്‘ എന്നാണ്.
സന്തോഷ് | 12-Feb-08 at 6:48 pm | Permalink
അകാരാദി: ‘അ’കാരം ആദിയില് വരുന്ന
ആകാരാദി: ‘ആ’കാരം ആദിയില് വരുന്ന
അങ്ങനെ നോക്കുമ്പോള് സിബുവിന്റെ ലിസ്റ്റ് അകാരാദിയുമല്ല, ആകാരാദിയുമല്ല.
സിബു | 12-Feb-08 at 6:56 pm | Permalink
അയ്യോ ‘അകാരാദി/ആകാരാദി’ എന്ന വാക്കില് എന്തിനാ ഇത്ര സമയം കളയുന്നത്. ഇനിമുതല് ഞാന് ‘കൊലേഷന്‘ വാക്കുപയോഗിക്കാം 🙂
Umesh:ഉമേഷ് | 13-Feb-08 at 4:44 pm | Permalink
സേര്ച്ച് എഞ്ചിനുകള് ജോയിനറുകളെ കളയുന്നതിനെപ്പറ്റി ഞാന് മനസ്സിലാക്കിയതു പോസ്റ്റിന്റെ അവസാനത്തില് കൊടുത്തിട്ടുണ്ടു്. ചുരുക്കം പറഞ്ഞാല്, ഗൂഗിളും വെബ് ദുനിയായും ജോയിനറുകളെ കളയുന്നു. (വെബ് ദുനിയാ കളയുന്നില്ല എന്നു തോന്നിപ്പിക്കുക മാത്രം ചെയ്യുന്നു.) യാഹുവും ലൈവ് സേര്ച്ചും കളയുന്നില്ല. ഇവയുടെ ഫലങ്ങളും പ്രത്യാഘാതങ്ങളും പോസ്റ്റില് ചേര്ത്തിട്ടുണ്ടു്.
അതോടൊപ്പം തന്നെ, ബ്രൌസറിലെയും സേര്ച്ച് എഞ്ചിനുകളിലെയും ബഗ്ഗുകളും രീതികളുമല്ല നമ്മുടെ വിഷയം എന്നും ഓര്ക്കുക. ചില ആപ്ലിക്കേഷനുകള് ജോയിനറുകളെ അവഗണിക്കുന്നുണ്ടെന്നും അതു യൂണിക്കോഡ് സ്റ്റാന്ഡേര്ഡിനു് എതിരല്ല എന്നുമാണു് ഞാന് പറയാന് ഉദ്ദേശിച്ച പോയിന്റ്. സേര്ച്ച് എഞ്ചിനുകളിലും മറ്റു് ആപ്ലിക്കേഷനുകളിലും നമുക്കു വേണ്ട ഫീച്ചറുകളെ ബഗ് ആയി റിപ്പോര്ട്ട് ചെയ്യുന്നതും അവ ഫിക്സു ചെയ്യിപ്പിക്കുന്നതും നല്ല കാര്യം തന്നെ.
Umesh:ഉമേഷ് | 14-Feb-08 at 1:53 am | Permalink
കുറേ ദിവസം തിരക്കിലായിരുന്നു. അതിനാല് കമന്റിടാനും മറ്റും കണ്ടില്ല. വിശദമായ മറുപടി വഴിയേ എഴുതാം. എങ്കിലും രണ്ടു കാര്യങ്ങള്ക്കു മറുപടി പറയണം എന്നു കരുതുന്നു.
ഒന്നു്, ഇവിടെ ചോദിക്കുന്ന ചോദ്യങ്ങള്ക്കു് ഞാന് തന്നെ മറുപടി പറയണം എന്നു ചിലര് ശാഠ്യം പിടിക്കുന്നതു് ഇവിടെയും പിന്നെ ഈ പോസ്റ്റിന്റെ കമന്റുകളിലും മറ്റു പലയിടത്തും കണ്ടു. അങ്ങനെയല്ല ഞാന് ഇതിനു മുമ്പും ബ്ലോഗ് കൈകാര്യം ചെയ്തിരുന്നതു്.
ഉദാഹരണമായി എന്റെ ന സ്ത്രീ സ്വാതന്ത്ര്യമര്ഹതി എന്ന പോസ്റ്റിലെ ഉള്ളടക്കത്തെപ്പറ്റി ധാരാളം പേര് വിയോജിപ്പു പ്രകടിപ്പിച്ചിരുന്നു. ആളുകള് രണ്ടു പക്ഷമായി നിന്നു ഘോരഘോരം വാദിച്ചു. ആദ്യത്തെ 44 കമന്റുകളില് (മൊത്തം 62 കമന്റുകള്) ഞാന് എഴുതിയതു് ഒന്നു മാത്രമാണു് (ആദ്യത്തേതു് ഒഴിച്ചാല്). അതില്ത്തന്നെ കാര്യമായി ഒന്നിനും മറുപടി പറഞ്ഞുമില്ല. അവിടെ കമന്റിട്ട ആരും “ഉമേഷ് തന്നെ മറുപടി പറയണം” എന്നു പറഞ്ഞു കേട്ടില്ല. എതിര്വാദങ്ങളെ ആളുകള് ശക്തമായിത്തന്നെ എതിര്ത്തു. എതിര്പ്പു വാദങ്ങളോടായിരുന്നു. വാദിക്കുന്ന ആളുകളോടായിരുന്നില്ല. ആളുകള് കൊടുക്കുന്ന മറുപടികളോടു് ഒന്നും കൂട്ടിച്ചേര്ക്കാനില്ലെങ്കില് ഞാന് കമന്റിടാന് മിനക്കെട്ടില്ല.
ഈ വാദത്തില് നിന്നു് എന്റെ ചില അഭിപ്രായങ്ങള്ക്കു മാറ്റവും സംഭവിച്ചു. രണ്ടു പക്ഷത്തെയും വാദങ്ങള് കേള്ക്കുക വഴി പ്രശ്നത്തെപ്പറ്റി കൂടുതല് അറിയാനും സാധിച്ചു. ഇവയെല്ലാം വേറൊരു പോസ്റ്റില് ക്രോഡീകരിച്ചു് മറുപടി പറയേണ്ടവയ്ക്കു മറുപടി പറഞ്ഞു. (തര്ക്കം അവിടെയും തുടര്ന്നു.)
അന്നു കൂടുതല് സമയമുണ്ടായിരുന്നതിനാല് അതു മൂന്നു ദിവസത്തിനുള്ളില് സാധിച്ചു. എന്നാല് ചിത്രകാരന്റെ ഈ പോസ്റ്റില് നടന്ന സംവാദത്തിന്റെ മറുപടി എഴുതിയതു് ഒന്നര മാസത്തിനു ശേഷം ഇവിടെ ആണു്.
ഇതു തന്നെയാണു് ഇവിടെയും ചെയ്യാന് ഉദ്ദേശിക്കുന്നതു്. ഇതില് നിന്നു പഠിച്ച കാര്യങ്ങളെ അവലംബിച്ചു് മറ്റൊരു പോസ്റ്റെഴുതാം. എന്റെ അഭിപ്രായങ്ങള് മാറിയിട്ടുണ്ടെങ്കില് അതും സൂചിപ്പിക്കാം. ഈ വാദം പണ്ടു നടന്ന ചില പോസ്റ്റുകളും ഡോ. മഹേഷ് മംഗലാട്ടിന്റെ പുതിയ പോസ്റ്റും ഇതിനിടെ വായിക്കാന് സാധിച്ചു. ഇവയിലെ വാദങ്ങളെല്ലാം അടുത്ത പോസ്റ്റില് പരാമര്ശിക്കാം.
അതിനിടയില് പൂര്വ്വവൈരാഗ്യം മൂലം മറ്റാരെങ്കിലും പറയുന്നതു കേള്ക്കാന് സന്മനസ്സില്ലെങ്കില് എനിക്കൊന്നും ചെയ്യാന് പറ്റില്ല. അതു മൂലം ഈ ത്രെഡ്ഡോ ബ്ലോഗോ ബോയ്ക്കോട്ട് ചെയ്യാന് തീരുമാനിച്ചാലും എനിക്കു വിരോധമില്ല.
രണ്ടു്, കൊലേഷനെപ്പറ്റി പ്രവീണ് നടത്തുന്ന ക്വിസ് പ്രോഗ്രാം ആണു്. അദ്ദേഹത്തിന്റെ ആദ്യത്തെ ചോദ്യം ഞാന് തെറ്റിദ്ധരിച്ചു മറുപടി പറഞ്ഞു. പിന്നീടാണു മനസ്സിലായതു് “ഊതുക” ആയിരുന്നെന്നു്. ഇത്തരം ചോദ്യങ്ങള്ക്കു് ഉത്തരം പറയാന് ഞാന് ഉദ്ദേശിച്ചിട്ടില്ല. കൊലേഷനെപ്പറ്റി അത്യാവശ്യം വിവരം എനിക്കുണ്ടെന്നാണു് എന്റെ വിശ്വാസം. പക്ഷേ, അതു് പ്രവീണിന്റെ ക്വിസ് പ്രോഗ്രാമിലെ ഓരോ ചോദ്യത്തിനും സ്കൂള് കുട്ടികളെപ്പോലെ മറുപടി പറഞ്ഞു തെളിയിക്കേണ്ട ആവശ്യമില്ല. ആവശ്യമുള്ളതും വായിക്കുന്നവര്ക്കു മനസ്സിലാകുന്നതുമായ കാര്യങ്ങളേ ഞാന് എഴുതാന് ഉദ്ദേശിക്കുന്നുള്ളൂ.
ക്വിസ് പ്രോഗ്രാം തന്നെ വേണമെങ്കില് ഞാന് പ്രവീണിനോടും ചോദിക്കാം, വ്യഞ്ജനങ്ങളെപ്പറ്റിയും ചില്ലിനെപ്പറ്റിയും അനുനാസികാദിപ്രസരത്തെപ്പറ്റിയും പേരെച്ചത്തെപ്പറ്റിയുമൊക്കെ. അല്ലെങ്കില് വേണ്ട, പ്രവീണ് ചോദിച്ചതു പോലെ തുടങ്ങാം: “മലയാളത്തിലെ ആദ്യത്തെ അക്ഷരമേതു്?” അതിനുത്തരം പറയാന് അറിവുണ്ടെങ്കില് രണ്ടാമത്തെ അക്ഷരമേതു് എന്നു ചോദിക്കാം 🙂
സന്തോഷ് തോട്ടിങ്ങല് | 14-Feb-08 at 6:44 am | Permalink
ഉമേഷ്ജി,
വിവിധ സെര്ച്ച് എന്ജിനുകളെ വിശകലനം ചെയ്തതിനു് നന്ദി.
യാഹൂവും ലൈവ് സെര്ച്ചും ജോയ്നറുകളെ അതേപോലെ ഉപയോഗിക്കുന്നതായും , ഗൂഗിള് സെര്ച്ച് റിസള്ട്ടിലും, സെര്ച്ചിലും
ജോയ്നറുകളെ കളയുന്നു. വെബ് ദുനിയയാകട്ടെ സെര്ച്ച് ചെയ്യുമ്പോള്
ജോയ്നര് കളയുകയും സെര്ച്ച് റിസള്ട്ടില് നിലനിര്ത്തുകയും ചെയ്യുന്നു.
ഇനി തത്കാലത്തേക്കു് ഇവയെ എല്ലാം മറക്കുക.
Suppose there is an application A which takes input I and produces output O.
Here we don’t know how A works. But we know that if we give I as input we will get O as output. i.e Consider A as a blackbox for the
time being. You may consider that for a software illiterate , the system is blackbox.
We assume that the output O contains a statement “Here is O and this is the output of input I”
Now, When a user gives I as input to A ,he expect the output for I.
Umeshji, tell me whether the above statement is correct or not?
If it is true, substitute സ്വപ്നം (with Non joiner ) for I.
Now suppose the system A as a whitebox. We know the functionality of A
Now we are going the anlayse how the system process I and how it produces O. Inside A, we know that there are processing stages
for input I. Assume that it goes through steps like I[1]. I[2], I[3]
etc..
and one of this , say I[k] is going to be the input of a subsystem A
[k] in A. And it produces an ouput O.
Now in the ouput , do we expect the statement
a) “Here is O, and this is the output of I[k]”
or
b)”Here is O, and this is the output of I”
IMHO, it is b)
Umeshji, Do you disagree with this?
Now substitute സ്വപ്നം (with Non joiner ) for I and a search system for A
OK, Now I am going to expand out I to S[1..n]
where S is a string with length n. and Length of S is defined as the number of bytes required to save S.
The application A takes S as input. The functionality of A demands processing/converting S[1..n] to many interemediate formats and these are going to be the input for different subsytems inside A.
Suppose at a particular stage k of A, say A[k]. A[k] changes S[1..n] to R[1..m] and
a) S==R or S!=R
b) n==m or n!=m
Now in the ouput , do we expect the statement
a) “Here is O, and this is the output of R[1..m]”
or
b) “Here is O, and this is the output of S[1..n]”
Now substitute സ്വപ്നം (with Non joiner ) for I and a search system for A
consider S[1..n] to R[1..m] convertion as a collation key conversion of S. As per unicode, the collation weight of ZWJ/ZWNJ is zero.
Next is to answer Cibu.
There is a sequence of applications A1 to An in an information network. UserA sends some data to UserB through this network.
Assume that one or more application in A1..An in the network is same as our previous A which converts S to R. Now there are many cases
a) UserA and UserB expects the data send by UserA is “same” as UserB recieves and that is why the network exists.
b) Now we need to define the word “same”. It depends on how a user
compares data1 to data2 to check whether data2 is same as data1. There are different ways for doing this. one way is to check the
size of data1 to data2. size of a data is defined as number of bytes required to save the data. Now if A[k] changes S[1..n] to R[1..m]
where n!=m, the size(data1)!= size(data2). If it is comparing data1 to data1 byte by byte, then also data1!=data2. Suppose the
comparison is done using unicodes standard by ignoring ZWJ/ZWNJ, and it is exaclty what S to R conversion, then data1 =data 2.
c) In the above case, if S to R conversion is done for the sake of processing an input to output and output says that it is not I , but I[k]was the input, and if that is buggy, then there is no point in saying that data1=data2
d) in case b, we found that the comparison is not always done by following Unicode rules. Many applications do not want to open the
file and do comparison. They just check the file size.
e) As a last point I want to mention about the mime type change or simply the file type change of data as Cibu explained with Notepad
->M$ word comparison. Suppose the user writes a ZWJ or ZWNJ in plain text. First of all why does he write it? If he knows that bold
or italics or underline does not work with plaintext, he will not write that characters in it. Am I right? So a normal user does not put bold italics or any other formating characters in plain text. But he writes
ZWJ/ZWNJ in that. Why? Knowing that any bug-free application (yes, I know that “at any point of time there is one more bug in any software”) will not ignore them while transferring data from one mimetype to another. He also knows that for processing inside application, the ZWJ or ZWNJ may not be used. But data remains as such. So your comparison of ZWJ/ZWNJ with italics or bold is wrong.
Now regarding the Zero collation weight of ZWJ and ZWNJ. It is the best way to implement an application which says the following pairs
are “same”
a) നന്മ നന്മ നന്മ
b)ബ്രഹ്മം ബ്രഹ്മം
c)റഹ്മാന് റഹ്മാന്
d)തമിഴ്നാട് തമിഴ്നാട്
etc
ഓര്ക്കുക ഞാനൊന്നും ന്യായീകരിക്കാന് ശ്രമിച്ചിട്ടില്ല. പകരം എന്റെ
അഭിപ്രായത്തില് അപ്ലിക്കേഷനുകള് ഐഡിയലായി എങ്ങനെ പെരുമാറണം എന്നു മാത്രമാണ് പറഞ്ഞത്. ഇതിനോടുള്ള ഉമേഷ്ജിയുടെ അഭിപ്രായം അറിഞ്ഞ ശേഷം ബാക്കി കാര്യങ്ങളിലേക്ക് പോകാം.
ഇനി വേറെ ചില കാര്യങ്ങള്:
നമ്മള് ചര്ച്ച ചെയ്തിട്ട് എന്തെങ്കിലും കാര്യമുണ്ടോന്ന് തോന്നുന്നുണ്ടോ
ഉമേഷ്ജിയ്ക്ക്? “It is already decided. Let us face whatever be the impact” ഇതിനോടു് ഉമേഷ്ജിക്ക് എന്താണു് പറയാനുള്ളതു്?
വേറൊന്നു്:
ആണവചില്ലു് വിവാദത്തിന്റെ വിവിധവശങ്ങളെക്കുറിച്ചു് ഡോ: മഹേഷ് മംഗലാട്ട് മാഷ് മാതൃഭൂമി ആഴ്ചപ്പതിപ്പില് ലേഖനമെഴുതിയിരിക്കുന്നു. സമയം
കിട്ടുകയാണെങ്കില് ഞാന് സ്കാന് ചെയ്ത് ബ്ലോഗിലിടാം.
Umesh:ഉമേഷ് | 14-Feb-08 at 6:52 am | Permalink
സന്തോഷ്,
വിശദമായ കമന്റിനു നന്ദി. ഞാന് മുഴുവന് വായിച്ചു തീര്ന്നില്ല. ഒരു കാര്യം പറയാനാണു് ഇതെഴുതുന്നതു്. ഡോ. മഹേഷിന്റെ ലേഖനം സ്കാന് ചെയ്യണമെന്നില്ല. അദ്ദേഹം തന്നെ അതു് ഇവിടെ ഇട്ടിട്ടുണ്ടു്. അതു തന്നെയല്ലേ ലേഖനം?
Benny | 14-Feb-08 at 8:35 am | Permalink
അപ്പോള് വെബ്ദുനിയ സെര്ച്ച് “വ്യത്യസ്തനാമൊരു ബാര്ബറാം ബാലന്” ആണല്ലേ 😛
P.C.Madhuraj | 14-Feb-08 at 12:06 pm | Permalink
സിബൂ,
നാനാര്ഥപദമായി കരുതിയാല്പോരെ ‘സദ്വാരത്തെ’?
ഉമേഷ് | Umesh | 14-Feb-08 at 3:42 pm | Permalink
ഹഹഹ ബെന്നീ 🙂
വെബ്ദുനിയയുടെ സേര്ച്ച് എഞ്ചിനെപ്പറ്റി അറിയില്ലായിരുന്നു. കൊള്ളാം. സേര്ച്ച് റിസല്ട്സ് കാണിക്കുമ്പോള് സേര്ച്ച് വേര്ഡ് ഹൈലൈറ്റു ചെയ്തു കാണിക്കുന്നില്ലല്ലോ പല കേസുകളിലും? സേര്ച്ച് വേര്ഡ് സ്പ്ലിറ്റു ചെയ്തു വെവ്വേറേ സേര്ച്ചു ചെയ്യുന്നതു (കണ്മണി പോലെ) കൊണ്ടാണോ അതു്?
മറ്റു സേര്ച്ച് എഞ്ചിനുകളുടെ രീതിയില് അനലൈസ് ചെയ്യാന് നോക്കിയപ്പോഴാണു് വെബ്ദുനിയാ മറ്റൊരു രീതിയിലാണു സേര്ച്ചു ചെയ്യുന്നതെന്നു കണ്ടതു്. ഭാരതീയഭാഷകള്ക്കു വേണ്ടി കൂടുതല് ഇന്റലിജന്സ് ഉള്ളതായും തോന്നി. അതുകൊണ്ടായിരുന്നു ആ പരാമര്ശം.
സന്തോഷ് തോട്ടിങ്ങല് | 18-Mar-08 at 7:46 am | Permalink
ഞാനെഴുതിയതു് ഉമേഷ്ജി വായിച്ചോ എന്തോ? ഒരു മാസമായപ്പൊ ഒന്നു വന്നു നോക്കിയതാ..
സിബു | 19-Mar-08 at 12:05 am | Permalink
സന്തോഷേ, ഡാറ്റ ഒരു പ്രോഗ്രാമുകളും ഉപേക്ഷിക്കാന് പാടില്ല എന്നല്ലേ ഇങ്ങനെ കോമ്പ്ലിക്കേറ്റഡായി പറഞ്ഞിരിക്കുന്നത്.
ഇതിനെ പറ്റി ഞാന് മുമ്പ് പറഞ്ഞതുതന്നെ ഇപ്പോഴും പറയാനുള്ളത് 🙁 ഡാറ്റയെ ഇന്റര്പ്രറ്റ് ചെയ്യുന്നവര് ഡാറ്റയുടെ ഉപയോഗമില്ലാത്ത ഭാഗങ്ങള് ഒഴിവാക്കും. ഉദാഹരണമായി, PNG ഇമേജിനെ സ്ക്രീനില് വരയ്ക്കുമ്പോള് (BMP) ലെയറുകളും ട്രാന്സ്പാരന്സിയും പോകുന്നപോലെ. ഡാറ്റയെ ഇന്റര്പ്രറ്റ് ചെയ്യാത്തവര് ഇന്ഫൊര്മേഷന് കളയരുത് എന്നത് സമ്മതിക്കുന്നു. പക്ഷെ, ഇവിടെ നമ്മള് ചര്ച്ച ചെയ്തുകൊണ്ടിരുന്നതുമുഴുവന് ലിംഗ്വിസ്റ്റിക് ഡാറ്റയെ ഇന്റര്പ്രറ്റ് ചെയ്യുന്ന പ്രോഗ്രാമുകളെയാണ്.
ഒരു കാര്യം കൂടി പറഞ്ഞോട്ടെ, ചില്ലിനെ പറ്റി ഇനി നമ്മള് ചര്ച്ച ചെയ്തിട്ട് കാര്യമുണ്ടെന്ന് തോന്നുന്നില്ല. ചില്ലുകള് അടുത്ത യുണീക്കോഡ് വെര്ഷനില് എത്തിക്കഴിഞ്ഞു.
കോവാല കൃഷ്ണന് | 19-Mar-08 at 4:34 am | Permalink
തോട്ടിങ്ങച്ചേട്ടായി മറുവടികള് ഞാമ്പറഞ്ഞാ മതിയാ. ഹിഹിഹി.
Jayarajan | 21-Feb-09 at 1:20 am | Permalink
ഇവിടെ ഒരു നൂറടിക്കാൻ ആരുമില്ലേ? എന്റെ 50-യെ ഉമേഷേട്ടൻ 44 ആക്കിക്കളഞ്ഞു; എന്നാപ്പിന്നെ കിടക്കട്ടെ ഒരു 100 🙂